Last updated on December 5, 2024

For those of you who don’t know me, my name is Ryan Saxe and I’ve been writing Limited content for StarCityGames.com for the last three years. This article is a result of my decision to pursue the intersection of my career (Machine Learning Scientist / Data Scientist) and my passion (Magic: the Gathering Draft).
For the last few months, I have been working with Draftsim to create a Magic: the Gathering draft agent. The purpose of this article is to explore the data provided by Draftsim, the architecture of my algorithm, the results for Throne of Eldraine, and how this model can be used to evaluate and understand future draft formats.
Think of this article as a teaser for what’s to come, as in the near future there will be a similar article for my bot’s learnings on Theros Beyond Death! Additionally, if you’re a mathematician, software developer, data scientist, or just curious, you can view the code for the agent on Github.
I am proud to say that my bot drafted a deck that I took to an undefeated record in a Magic Online event. In fact, I believe this is the first case of an MTG AI demonstrating success in a competitive setting.
There are two main reasons I set out to design this draft bot. First and foremost, I want to demonstrate that this is an approachable task with fruitful and deep areas to explore. While I am unsure how the bots on MTG Arena work, I believe there is a lot of room for improvement, and I wanted to explore what a more dynamic bot would look like.
Secondly, I attempted this task as a motivator to think about the fundamental mathematics that govern decision making in draft, which would be the foundation of my AI. This design is what differentiates my bot from the way others have approached this same problem. Furthermore, this approach creates a much more interpretable algorithm, and allows me to write an article like this one that truly delves into the inner machinations of how this bot makes decisions.
Let’s start with an overview of the data, then take a look at the three priors that I incorporated into my model. Finally, you’ll get to see just how well it performed when I put it all together.
What Does the Data Look Like?
To start this project, Draftsim gave me a file with over 80,000 drafts of Throne of Eldraine completed on their website. That’s well over 3-million data points (picks), and hence plenty of data for a machine learning algorithm. Unfortunately, after inspection of the drafts, about 35,000 were not sufficient (incomplete, duplicate, etc.), leaving approximately 2-million data points. Luckily, this is still sufficiently large data for a machine learning algorithm.
I then randomly split the data — keeping drafts together to avoid leakage — such that I use 80% of the data to train the model, and 20% of the data to test it (I excluded a validation set because I wanted the test set to be sufficiently large and I didn’t employ any hyperparameter tuning. This will likely change in the near future). Each data point consists of the pool of cards the player drafted so far, the pack they selected from, and the card they selected from that pack.

80,000 drafts just like yours on Draftsim helped make this analysis possible
However, this dataset has a significant problem: the environment doesn’t represent the real world. First, drafting on Draftsim is with bots that don’t navigate drafts like people do. Second, there’s neither risk (entry fee) nor incentive (prize pool). And finally, while the average skill-level of users across Draftsim is unknown, the sample size of this dataset is so large that it is unlikely to represent expert-level drafting at a high density.
Hence treating this dataset like a beautiful oracle, and attempting to create a bot that exactly mimics the users would not necessarily generate a sufficient Draft agent. In order to design an algorithm that would not succumb to the pitfalls of the dataset, I attempted to construct it with reasonable priors based on my expert knowledge of Magic: the Gathering draft. Throughout this article I believe I sufficiently demonstrate that I was successful in my endeavor by juxtaposing the tendencies of my bot’s behavior with human behavior from the dataset.
First Prior: Set of Archetypes
Every single limited format has a set of archetypes predefined by Wizards of the Coast, often correlated with color combinations. Sometimes there’s a novel addition like Clear the Mind in Ravnica Allegiance, but this nuance is less necessary to capture, and creating the architecture to enable an AI to discover archetypal subtleties is out of the scope of this current project. However, I do intend on exploring this in the future.
Instead, I started with an initial exploration of global archetypes:
| arch | count |
|---|---|
| UG | 3133 |
| WR | 2651 |
| WU | 2097 |
| G | 3353 |
| W | 1582 |
| B | 1821 |
| UR | 4016 |
| R | 1937 |
| RG | 2830 |
| BR | 2822 |
| WG | 3032 |
| WB | 2442 |
| BG | 5679 |
| UB | 3658 |
| U | 3627 |
These archetypal labels are computed via K-means clustering for fifteen clusters, because Throne of Eldraine has fifteen unique archetypes. I took all 45,000 drafts, grabbed their final pools, computed the total number of cards per color, and found fifteen clusters that perfectly separate into all color-combinations and mono-colored archetypes.
One thing I found surprising is that the mono-colored archetypes have a smaller slice of the pie than I expected, as I believe Throne of Eldraine rewards those archetypes significantly. I’m proud to demonstrate that this isn’t the case with my bot! I generated 5,000 drafts with eight copies of my bot, and computed the average number of drafters per table for each archetype. The difference between my bot’s distribution of archetypes and the data’s distribution of archetypes is staggering.
| arch | human_expected | bot_expected |
|---|---|---|
| UG | 0.5609668755595345 | 0.1972 |
| WR | 0.4746642793196061 | 0.2804 |
| WU | 0.3754700089525515 | 0.2804 |
| G | 0.6003581020590868 | 0.8508 |
| W | 0.28325872873769026 | 1.0732 |
| B | 0.3260519247985676 | 1.1626 |
| UR | 0.7190689346463742 | 0.3934 |
| R | 0.3468218442256043 | 1.0132 |
| RG | 0.5067144136078783 | 0.1764 |
| BR | 0.5052820053715309 | 0.269 |
| WG | 0.5428827215756491 | 0.2404 |
| WB | 0.43724261414503135 | 0.2948 |
| BG | 1.0168307967770815 | 0.4662 |
| UB | 0.65496866606983 | 0.3824 |
| U | 0.6494180841539838 | 0.9526 |
So, how did I get here? How did the bot deviate so far, and in what I believe is a good and functional manner, from the dataset? And how did clustering play an important role?
When I sit down to draft, I’m not taking cards randomly. Each card I take has some distribution explaining how good it is in each archetype. Merfolk Secretkeeper pulls me much harder to Dimir than it does to Simic. This is why a global pick order falls apart so quickly in draft; the context of colors and archetypal biases in a draft pool has a drastic impact on the prioritization of cards in the following packs.
So, in order to give my model a representation of archetypes to embed this nuance, I chunked the training dataset by the K-means clusters and trained a linear model for each archetype by feeding it only data from Pack 2 Pick 3 onwards for that specific archetype.
| UG | WR | WU | G | W | B | UR | R | RG | BR | WG | WB | BG | UB | U | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | The_Great_Henge | The_Circle_of_Loyalty | Stolen_by_the_Fae | Wicked_Wolf | Stonecoil_Serpent | Rankle_Master_of_Pranks | Irencrag_Pyromancer | Bonecrusher_Giant | Bonecrusher_Giant | Embercleave | The_Great_Henge | The_Circle_of_Loyalty | Garruk_Cursed_Huntsman | Rankle_Master_of_Pranks | Stolen_by_the_Fae |
| 1 | Oko_Thief_of_Crowns | Bonecrusher_Giant | Harmonious_Archon | Feasting_Troll_King | Harmonious_Archon | Murderous_Rider | The_Royal_Scions | Embercleave | Questing_Beast | Murderous_Rider | Stonecoil_Serpent | Murderous_Rider | Questing_Beast | Clackbridge_Troll | Gadwick_the_Wizened |
| 2 | Questing_Beast | Embercleave | Brazen_Borrower | Garruk_Cursed_Huntsman | Giant_Killer | Clackbridge_Troll | Brazen_Borrower | Opportunistic_Dragon | Embercleave | Rankle_Master_of_Pranks | Realm-Cloaked_Giant | Clackbridge_Troll | Rankle_Master_of_Pranks | Murderous_Rider | Brazen_Borrower |
| 3 | Wicked_Wolf | Worthy_Knight | Giant_Killer | The_Great_Henge | Realm-Cloaked_Giant | Piper_of_the_Swarm | Opportunistic_Dragon | Torbran_Thane_of_Red_Fell | Wicked_Wolf | Blacklance_Paragon | Wicked_Wolf | Stonecoil_Serpent | Murderous_Rider | Stonecoil_Serpent | Stonecoil_Serpent |
| 4 | Brazen_Borrower | Opportunistic_Dragon | Realm-Cloaked_Giant | Gilded_Goose | Worthy_Knight | Garruk_Cursed_Huntsman | Bonecrusher_Giant | Robber_of_the_Rich | Opportunistic_Dragon | Clackbridge_Troll | Giant_Killer | Realm-Cloaked_Giant | Clackbridge_Troll | Stolen_by_the_Fae | Vantress_Gargoyle |
| 5 | Feasting_Troll_King | Stonecoil_Serpent | Stonecoil_Serpent | Lovestruck_Beast | The_Circle_of_Loyalty | Stonecoil_Serpent | Stolen_by_the_Fae | Slaying_Fire | Lovestruck_Beast | Opportunistic_Dragon | Lovestruck_Beast | Blacklance_Paragon | The_Great_Henge | Brazen_Borrower | Folio_of_Fancies |
| 6 | Stonecoil_Serpent | Acclaimed_Contender | Gadwick_the_Wizened | Questing_Beast | Syr_Alin_the_Lion's_Claw | Blacklance_Paragon | Embercleave | Sundering_Stroke | The_Great_Henge | Bonecrusher_Giant | Harmonious_Archon | Oathsworn_Knight | Wicked_Wolf | Lochmere_Serpent | Midnight_Clock |
| 7 | Garruk_Cursed_Huntsman | Outlaws'_Merriment | The_Circle_of_Loyalty | Yorvo_Lord_of_Garenbrig | Acclaimed_Contender | Syr_Konrad_the_Grim | Stonecoil_Serpent | Stonecoil_Serpent | Feasting_Troll_King | Oathsworn_Knight | Wildborn_Preserver | Worthy_Knight | Feasting_Troll_King | Gadwick_the_Wizened | Syr_Elenora_the_Discerning |
| 8 | Lovestruck_Beast | Harmonious_Archon | Arcanist's_Owl | Wildborn_Preserver | Charming_Prince | Oathsworn_Knight | Loch_Dragon | Irencrag_Pyromancer | Stonecoil_Serpent | Stonecoil_Serpent | Feasting_Troll_King | Piper_of_the_Swarm | Stonecoil_Serpent | Piper_of_the_Swarm | Hypnotic_Sprite |
| 9 | Stolen_by_the_Fae | Inspiring_Veteran | Vantress_Gargoyle | Oko_Thief_of_Crowns | Ardenvale_Tactician | Bake_into_a_Pie | Gadwick_the_Wizened | Scorching_Dragonfire | Wildborn_Preserver | Syr_Konrad_the_Grim | Questing_Beast | Giant_Killer | Gilded_Goose | Vantress_Gargoyle | Faerie_Vandal |
| 10 | Wildborn_Preserver | Fireborn_Knight | Midnight_Clock | Stonecoil_Serpent | Archon_of_Absolution | Ayara_First_of_Locthwain | Robber_of_the_Rich | Syr_Carah_the_Bold | Garruk_Cursed_Huntsman | Piper_of_the_Swarm | Gilded_Goose | Rankle_Master_of_Pranks | Lovestruck_Beast | Syr_Konrad_the_Grim | Oko_Thief_of_Crowns |
| 11 | Gilded_Goose | Syr_Alin_the_Lion's_Claw | Glass_Casket | Return_of_the_Wildspeaker | Linden_the_Steadfast_Queen | Epic_Downfall | Improbable_Alliance | Searing_Barrage | Gilded_Goose | Garruk_Cursed_Huntsman | Garruk_Cursed_Huntsman | Harmonious_Archon | Wildborn_Preserver | Folio_of_Fancies | Fae_of_Wishes |
| 12 | Gadwick_the_Wizened | Giant_Killer | Charming_Prince | Keeper_of_Fables | Glass_Casket | Order_of_Midnight | Faerie_Vandal | The_Royal_Scions | Robber_of_the_Rich | Robber_of_the_Rich | The_Circle_of_Loyalty | Syr_Konrad_the_Grim | Piper_of_the_Swarm | Epic_Downfall | The_Royal_Scions |
| 13 | Yorvo_Lord_of_Garenbrig | Torbran_Thane_of_Red_Fell | Archon_of_Absolution | Beanstalk_Giant | Mysterious_Pathlighter | Witch's_Vengeance | Syr_Elenora_the_Discerning | Burning-Yard_Trainer | Yorvo_Lord_of_Garenbrig | Syr_Carah_the_Bold | Oakhame_Ranger | Order_of_Midnight | Savvy_Hunter | Bake_into_a_Pie | Charmed_Sleep |
| 14 | Return_of_the_Wildspeaker | Realm-Cloaked_Giant | Animating_Faerie | Rankle_Master_of_Pranks | Rankle_Master_of_Pranks | Foulmire_Knight | Slaying_Fire | Fervent_Champion | Torbran_Thane_of_Red_Fell | Torbran_Thane_of_Red_Fell | Yorvo_Lord_of_Garenbrig | Acclaimed_Contender | Oko_Thief_of_Crowns | Witch's_Vengeance | Lochmere_Serpent |
| 15 | Midnight_Clock | Robber_of_the_Rich | Syr_Alin_the_Lion's_Claw | Clackbridge_Troll | Questing_Beast | Questing_Beast | Torbran_Thane_of_Red_Fell | Joust | Return_of_the_Wildspeaker | Epic_Downfall | Wandermare | Epic_Downfall | Yorvo_Lord_of_Garenbrig | Blacklance_Paragon | Turn_into_a_Pumpkin |
| 16 | Beanstalk_Giant | Slaying_Fire | Emry_Lurker_of_the_Loch | Fierce_Witchstalker | Trapped_in_the_Tower | Revenge_of_Ravens | Mad_Ratter | Fireborn_Knight | Rampart_Smasher | Stormfist_Crusader | Syr_Alin_the_Lion's_Claw | Garruk_Cursed_Huntsman | Bake_into_a_Pie | Garruk_Cursed_Huntsman | Animating_Faerie |
| 17 | Keeper_of_Fables | Syr_Carah_the_Bold | Oko_Thief_of_Crowns | Oakhame_Adversary | Castle_Ardenvale | Bog_Naughty | Vantress_Gargoyle | Elite_Headhunter | Grumgully_the_Generous | Slaying_Fire | Beanstalk_Giant | Syr_Alin_the_Lion's_Claw | Syr_Konrad_the_Grim | Covetous_Urge | Rankle_Master_of_Pranks |
| 18 | Vantress_Gargoyle | Sundering_Stroke | Fae_of_Wishes | Outmuscle | Fireborn_Knight | Reave_Soul | Syr_Carah_the_Bold | Redcap_Melee | Slaying_Fire | Bake_into_a_Pie | Edgewall_Innkeeper | Resolute_Rider | Epic_Downfall | Syr_Elenora_the_Discerning | Garruk_Cursed_Huntsman |
| 19 | Maraleaf_Pixie | Glass_Casket | Folio_of_Fancies | Edgewall_Innkeeper | Embercleave | Oko_Thief_of_Crowns | Sundering_Stroke | The_Great_Henge | Keeper_of_Fables | Order_of_Midnight | Oko_Thief_of_Crowns | Bake_into_a_Pie | Deathless_Knight | Order_of_Midnight | Tome_Raider |
| 20 | Thunderous_Snapper | Fervent_Champion | Hypnotic_Sprite | Once_Upon_a_Time | Resolute_Rider | Wicked_Wolf | Scorching_Dragonfire | Rampart_Smasher | Sundering_Stroke | Elite_Headhunter | Faeburrow_Elder | Wintermoor_Commander | Return_of_the_Wildspeaker | Oathsworn_Knight | Merfolk_Secretkeeper |
| 21 | Syr_Elenora_the_Discerning | Ardenvale_Tactician | Syr_Elenora_the_Discerning | Deathless_Knight | Venerable_Knight | The_Cauldron_of_Eternity | Folio_of_Fancies | Loch_Dragon | Oko_Thief_of_Crowns | Sundering_Stroke | Mysterious_Pathlighter | Foulmire_Knight | Oathsworn_Knight | Midnight_Clock | Emry_Lurker_of_the_Loch |
| 22 | Oakhame_Adversary | Scorching_Dragonfire | Shinechaser | Syr_Faren_the_Hengehammer | Shepherd_of_the_Flock | Deathless_Knight | Midnight_Clock | Garruk_Cursed_Huntsman | Beanstalk_Giant | Belle_of_the_Brawl | Return_of_the_Wildspeaker | Belle_of_the_Brawl | Order_of_Midnight | Oko_Thief_of_Crowns | Loch_Dragon |
| 23 | Fae_of_Wishes | Archon_of_Absolution | Worthy_Knight | Murderous_Rider | Oakhame_Ranger | Realm-Cloaked_Giant | Oko_Thief_of_Crowns | Embereth_Shieldbreaker | Syr_Carah_the_Bold | Steelclaw_Lance | Archon_of_Absolution | Witch's_Vengeance | Bog_Naughty | Hypnotic_Sprite | Clackbridge_Troll |
| 24 | Hypnotic_Sprite | Garruk_Cursed_Huntsman | Charmed_Sleep | Embercleave | Garruk_Cursed_Huntsman | Belle_of_the_Brawl | Turn_into_a_Pumpkin | Rimrock_Knight | Scorching_Dragonfire | Foulmire_Knight | Keeper_of_Fables | Charming_Prince | Beanstalk_Giant | Revenge_of_Ravens | Murderous_Rider |
| 25 | Fierce_Witchstalker | Joust | Linden_the_Steadfast_Queen | Piper_of_the_Swarm | Hushbringer | Covetous_Urge | Fae_of_Wishes | Oko_Thief_of_Crowns | Syr_Faren_the_Hengehammer | Scorching_Dragonfire | Glass_Casket | Glass_Casket | Witch's_Vengeance | Drown_in_the_Loch | Questing_Beast |
| 26 | Once_Upon_a_Time | Fabled_Passage | Trapped_in_the_Tower | Trail_of_Crumbs | Youthful_Knight | Castle_Locthwain | Hypnotic_Sprite | Questing_Beast | Outmuscle | Witch's_Vengeance | Charming_Prince | Archon_of_Absolution | Blacklance_Paragon | Reave_Soul | Covetous_Urge |
| 27 | Fabled_Passage | Charming_Prince | Ardenvale_Tactician | Rosethorn_Acolyte | Outlaws'_Merriment | Feasting_Troll_King | Animating_Faerie | Rankle_Master_of_Pranks | Irencrag_Pyromancer | Fervent_Champion | Fierce_Witchstalker | Revenge_of_Ravens | Fierce_Witchstalker | Turn_into_a_Pumpkin | Castle_Vantress |
| 28 | Folio_of_Fancies | Burning-Yard_Trainer | Garruk_Cursed_Huntsman | Epic_Downfall | Arcanist's_Owl | The_Circle_of_Loyalty | Tome_Raider | Mad_Ratter | Fierce_Witchstalker | Reave_Soul | Ardenvale_Tactician | Reave_Soul | Foulmire_Knight | Fae_of_Wishes | Overwhelmed_Apprentice |
| 29 | Syr_Faren_the_Hengehammer | Irencrag_Pyromancer | Fabled_Passage | Bake_into_a_Pie | Oathsworn_Knight | Fabled_Passage | Charmed_Sleep | The_Circle_of_Loyalty | Once_Upon_a_Time | Irencrag_Pyromancer | Syr_Faren_the_Hengehammer | Ardenvale_Tactician | Keeper_of_Fables | Ayara_First_of_Locthwain | Frogify |
| 30 | Outmuscle | Trapped_in_the_Tower | Faerie_Vandal | Savvy_Hunter | Brazen_Borrower | Resolute_Rider | Searing_Barrage | Castle_Embereth | Oakhame_Adversary | Revenge_of_Ravens | Shepherd_of_the_Flock | Embercleave | Reave_Soul | Animating_Faerie | Bonecrusher_Giant |
| 31 | Faerie_Vandal | Venerable_Knight | Acclaimed_Contender | Rampart_Smasher | Clackbridge_Troll | Lochmere_Serpent | Sage_of_the_Falls | Piper_of_the_Swarm | Searing_Barrage | Burning-Yard_Trainer | Lucky_Clover | Ayara_First_of_Locthwain | Revenge_of_Ravens | Foulmire_Knight | Into_the_Story |
| 32 | Charmed_Sleep | Linden_the_Steadfast_Queen | Turn_into_a_Pumpkin | Fabled_Passage | Faerie_Guidemother | Elite_Headhunter | Garruk_Cursed_Huntsman | Murderous_Rider | Fabled_Passage | Joust | Oakhame_Adversary | Questing_Beast | Trail_of_Crumbs | Charmed_Sleep | Embercleave |
| 33 | Animating_Faerie | Castle_Ardenvale | Mysterious_Pathlighter | Realm-Cloaked_Giant | Flutterfox | Brazen_Borrower | Emry_Lurker_of_the_Loch | Realm-Cloaked_Giant | The_Royal_Scions | Fabled_Passage | Outmuscle | Venerable_Knight | Oakhame_Adversary | Faerie_Vandal | Irencrag_Pyromancer |
| 34 | Turn_into_a_Pumpkin | Searing_Barrage | Castle_Vantress | Lucky_Clover | Bonecrusher_Giant | Witch's_Oven | Merchant_of_the_Vale | Raging_Redcap | Redcap_Melee | The_Cauldron_of_Eternity | Trapped_in_the_Tower | Trapped_in_the_Tower | Ayara_First_of_Locthwain | Emry_Lurker_of_the_Loch | Sage_of_the_Falls |
| 35 | Edgewall_Innkeeper | Redcap_Melee | The_Royal_Scions | Syr_Konrad_the_Grim | Blacklance_Paragon | Smitten_Swordmaster | Redcap_Melee | Merchant_of_the_Vale | Edgewall_Innkeeper | Smitten_Swordmaster | Worthy_Knight | Smitten_Swordmaster | Outmuscle | Merfolk_Secretkeeper | Arcanist's_Owl |
| 36 | Lochmere_Serpent | Embereth_Shieldbreaker | Lucky_Clover | Castle_Garenbrig | Opportunistic_Dragon | Lovestruck_Beast | Castle_Vantress | Brimstone_Trebuchet | Realm-Cloaked_Giant | Ayara_First_of_Locthwain | Once_Upon_a_Time | Mysterious_Pathlighter | Once_Upon_a_Time | The_Cauldron_of_Eternity | Queen_of_Ice |
| 37 | Rankle_Master_of_Pranks | Murderous_Rider | Mirrormade | Garenbrig_Paladin | Lovestruck_Beast | Foreboding_Fruit | Questing_Beast | Seven_Dwarves | Fervent_Champion | Embereth_Shieldbreaker | Fabled_Passage | The_Cauldron_of_Eternity | Syr_Faren_the_Hengehammer | Fabled_Passage | Didn't_Say_Please |
| 38 | Rosethorn_Acolyte | Rankle_Master_of_Pranks | Shepherd_of_the_Flock | Thunderous_Snapper | The_Great_Henge | Cauldron_Familiar | Frogify | Oathsworn_Knight | Escape_to_the_Wilds | Questing_Beast | Acclaimed_Contender | Castle_Ardenvale | Edgewall_Innkeeper | Overwhelmed_Apprentice | Run_Away_Together |
| 39 | Embercleave | Mysterious_Pathlighter | Enchanted_Carriage | Giant_Opportunity | Silverflame_Squire | Tempting_Witch | Lochmere_Serpent | Heraldic_Banner | Rankle_Master_of_Pranks | Redcap_Melee | Linden_the_Steadfast_Queen | Linden_the_Steadfast_Queen | The_Cauldron_of_Eternity | Bog_Naughty | So_Tiny |
| 40 | Tome_Raider | Rimrock_Knight | Tome_Raider | Oakhame_Ranger | Murderous_Rider | Lost_Legion | Fabled_Passage | Clockwork_Servant | Embereth_Shieldbreaker | Searing_Barrage | Rosethorn_Acolyte | Shepherd_of_the_Flock | Giant_Opportunity | The_Royal_Scions | Piper_of_the_Swarm |
| 41 | Clackbridge_Troll | Shepherd_of_the_Flock | Castle_Ardenvale | Curious_Pair | Rally_for_the_Throne | Gilded_Goose | Queen_of_Ice | Ogre_Errant | Rosethorn_Acolyte | Oko_Thief_of_Crowns | Hushbringer | Castle_Locthwain | Lochmere_Serpent | Castle_Locthwain | Mirrormade |
| 42 | Frogify | Youthful_Knight | Clockwork_Servant | Once_and_Future | Robber_of_the_Rich | Savvy_Hunter | Spinning_Wheel | Blacklance_Paragon | Joust | Harmonious_Archon | Murderous_Rider | Bog_Naughty | Belle_of_the_Brawl | Tome_Raider | Syr_Konrad_the_Grim |
| 43 | Emry_Lurker_of_the_Loch | Clackbridge_Troll | Frogify | Bonecrusher_Giant | Scalding_Cauldron | Clockwork_Servant | Opt | Brazen_Borrower | Rimrock_Knight | Bog_Naughty | Castle_Ardenvale | Outlaws'_Merriment | Witch's_Oven | Castle_Vantress | Wicked_Wolf |
| 44 | The_Royal_Scions | Brimstone_Trebuchet | Questing_Beast | Kenrith's_Transformation | Sundering_Stroke | Yorvo_Lord_of_Garenbrig | Into_the_Story | Stormfist_Crusader | Castle_Embereth | Castle_Locthwain | Faerie_Guidemother | Robber_of_the_Rich | Tempting_Witch | Questing_Beast | Lucky_Clover |
| 45 | Trail_of_Crumbs | Resolute_Rider | Lochmere_Serpent | Brazen_Borrower | Lonesome_Unicorn | Lucky_Clover | Embereth_Shieldbreaker | Thrill_of_Possibility | Kenrith's_Transformation | Rimrock_Knight | Embercleave | Fabled_Passage | Fabled_Passage | Queen_of_Ice | Opportunistic_Dragon |
| 46 | Giant_Opportunity | Heraldic_Banner | Flutterfox | Harmonious_Archon | Lucky_Clover | Giant_Killer | Murderous_Rider | Outlaws'_Merriment | Burning-Yard_Trainer | Brazen_Borrower | Spinning_Wheel | Youthful_Knight | Embercleave | Into_the_Story | Epic_Downfall |
| 47 | Lucky_Clover | Oathsworn_Knight | Spinning_Wheel | Bog_Naughty | Heraldic_Banner | Locthwain_Paladin | Realm-Cloaked_Giant | Feasting_Troll_King | Castle_Garenbrig | Giant_Killer | Trail_of_Crumbs | Oko_Thief_of_Crowns | Castle_Locthwain | The_Great_Henge | Witching_Well |
| 48 | Queen_of_Ice | The_Royal_Scions | Scalding_Cauldron | Lochmere_Serpent | Oko_Thief_of_Crowns | Heraldic_Banner | Run_Away_Together | Clackbridge_Troll | Once_and_Future | The_Circle_of_Loyalty | Silverflame_Squire | Lucky_Clover | Rosethorn_Acolyte | Frogify | Opt |
| 49 | Into_the_Story | Hushbringer | Hushbringer | Foulmire_Knight | Epic_Downfall | Wildborn_Preserver | Castle_Embereth | Weaselback_Redcap | Garenbrig_Paladin | Resolute_Rider | Curious_Pair | Doom_Foretold | Curious_Pair | Belle_of_the_Brawl | Bake_into_a_Pie |
| 50 | Once_and_Future | Oko_Thief_of_Crowns | Dance_of_the_Manse | Blacklance_Paragon | Enchanted_Carriage | Harmonious_Archon | Witching_Well | Bake_into_a_Pie | Lucky_Clover | Brimstone_Trebuchet | Lonesome_Unicorn | Fireborn_Knight | Kenrith's_Transformation | Didn't_Say_Please | Golden_Egg |
| 51 | Kenrith's_Transformation | Brazen_Borrower | Rankle_Master_of_Pranks | Giant_Killer | Clockwork_Servant | The_Great_Henge | Thrill_of_Possibility | Order_of_Midnight | Trail_of_Crumbs | Fireborn_Knight | Clackbridge_Troll | Lost_Legion | Realm-Cloaked_Giant | So_Tiny | Slaying_Fire |
| 52 | Castle_Vantress | The_Great_Henge | Clackbridge_Troll | Spinning_Wheel | Piper_of_the_Swarm | Robber_of_the_Rich | Fervent_Champion | Embereth_Paladin | Raging_Redcap | Heraldic_Banner | Garenbrig_Paladin | Lochmere_Serpent | Spinning_Wheel | Sage_of_the_Falls | Fabled_Passage |
| 53 | Castle_Garenbrig | Raging_Redcap | Golden_Egg | Oathsworn_Knight | Outflank | Bonecrusher_Giant | Golden_Egg | Bloodhaze_Wolverine | Merchant_of_the_Vale | The_Royal_Scions | Garenbrig_Carver | Bonecrusher_Giant | Cauldron_Familiar | Spinning_Wheel | Sundering_Stroke |
| 54 | Bonecrusher_Giant | Piper_of_the_Swarm | Queen_of_Ice | Order_of_Midnight | Wicked_Wolf | Cauldron's_Gift | So_Tiny | Fabled_Passage | Ferocity_of_the_Wilds | Ogre_Errant | Kenrith's_Transformation | Silverflame_Squire | Smitten_Swordmaster | Run_Away_Together | Clockwork_Servant |
| 55 | Spinning_Wheel | Questing_Beast | The_Great_Henge | Witch's_Vengeance | Fabled_Passage | Forever_Young | Bloodhaze_Wolverine | Redcap_Raiders | Spinning_Wheel | Worthy_Knight | Tuinvale_Treefolk | Enchanted_Carriage | Harmonious_Archon | Mirrormade | Spinning_Wheel |
| 56 | Sage_of_the_Falls | Castle_Embereth | Bonecrusher_Giant | Witch's_Oven | Prized_Griffin | Wishclaw_Talisman | The_Magic_Mirror | Enchanted_Carriage | Murderous_Rider | Castle_Embereth | Once_and_Future | Hushbringer | Once_and_Future | Witch's_Oven | Harmonious_Archon |
| 57 | Realm-Cloaked_Giant | Blacklance_Paragon | Into_the_Story | Tuinvale_Treefolk | Wildborn_Preserver | Embercleave | Joust | Witch's_Vengeance | Harmonious_Archon | Raging_Redcap | Castle_Garenbrig | Witch's_Oven | Brazen_Borrower | Lucky_Clover | The_Magic_Mirror |
| 58 | Murderous_Rider | Ogre_Errant | Heraldic_Banner | The_Circle_of_Loyalty | Spinning_Wheel | Malevolent_Noble | Mirrormade | Epic_Downfall | Enchanted_Carriage | Lost_Legion | Heraldic_Banner | Brazen_Borrower | Castle_Garenbrig | Enchanted_Carriage | Torbran_Thane_of_Red_Fell |
| 59 | Enchanted_Carriage | Enchanted_Carriage | All_That_Glitters | Reave_Soul | Order_of_Midnight | Fierce_Witchstalker | Enchanted_Carriage | Wildborn_Preserver | Mad_Ratter | Foreboding_Fruit | Venerable_Knight | Torbran_Thane_of_Red_Fell | Golden_Egg | Clockwork_Servant | Improbable_Alliance |
| 60 | Merfolk_Secretkeeper | Faerie_Guidemother | The_Magic_Mirror | Robber_of_the_Rich | Torbran_Thane_of_Red_Fell | Gadwick_the_Wizened | Overwhelmed_Apprentice | Spinning_Wheel | Heraldic_Banner | Realm-Cloaked_Giant | Giant_Opportunity | Locthwain_Paladin | Lucky_Clover | Torbran_Thane_of_Red_Fell | Lovestruck_Beast |
| 61 | Garenbrig_Paladin | Lucky_Clover | So_Tiny | Garenbrig_Carver | Bake_into_a_Pie | Return_of_the_Wildspeaker | Merfolk_Secretkeeper | Wicked_Wolf | Tuinvale_Treefolk | The_Great_Henge | Flutterfox | Clockwork_Servant | Foreboding_Fruit | Tempting_Witch | Realm-Cloaked_Giant |
| 62 | Mirrormade | Rally_for_the_Throne | Sage_of_the_Falls | Clockwork_Servant | Inspiring_Veteran | Sundering_Stroke | Heraldic_Banner | Syr_Konrad_the_Grim | Loch_Dragon | Acclaimed_Contender | Enchanted_Carriage | Faerie_Guidemother | Garenbrig_Paladin | Foreboding_Fruit | Mystical_Dispute |
| 63 | Rampart_Smasher | Tournament_Grounds | Murderous_Rider | Maraleaf_Rider | Syr_Carah_the_Bold | Oakhame_Adversary | Steelgaze_Griffin | Inspiring_Veteran | Brazen_Borrower | Mad_Ratter | Outlaws'_Merriment | Scalding_Cauldron | Enchanted_Carriage | Golden_Egg | Heraldic_Banner |
| 64 | Clockwork_Servant | Elite_Headhunter | Shambling_Suit | Ayara_First_of_Locthwain | Slaying_Fire | The_Royal_Scions | Rankle_Master_of_Pranks | Belle_of_the_Brawl | Giant_Opportunity | Locthwain_Paladin | Golden_Egg | Heraldic_Banner | Resolute_Rider | Witching_Well | The_Circle_of_Loyalty |
| 65 | Overwhelmed_Apprentice | Silverflame_Squire | Embercleave | Heraldic_Banner | Silverflame_Ritual | Syr_Faren_the_Hengehammer | The_Great_Henge | Ferocity_of_the_Wilds | Deathless_Knight | Deathless_Knight | Clockwork_Servant | Lonesome_Unicorn | Lost_Legion | Forever_Young | Robber_of_the_Rich |
| 66 | Run_Away_Together | Order_of_Midnight | Run_Away_Together | Sundering_Stroke | Reave_Soul | Golden_Egg | The_Circle_of_Loyalty | Skullknocker_Ogre | Piper_of_the_Swarm | Scalding_Cauldron | Bonecrusher_Giant | Deathless_Knight | Opportunistic_Dragon | The_Circle_of_Loyalty | Vantress_Paladin |
| 67 | Heraldic_Banner | Spinning_Wheel | Feasting_Troll_King | Flaxen_Intruder | Foulmire_Knight | Reaper_of_Night | Unexplained_Vision | Giant_Killer | Garenbrig_Carver | Outlaws'_Merriment | Deathless_Knight | Rally_for_the_Throne | Bonecrusher_Giant | Harmonious_Archon | Enchanted_Carriage |
| 68 | So_Tiny | Lonesome_Unicorn | Witching_Well | Golden_Egg | Wintermoor_Commander | Midnight_Clock | Didn't_Say_Please | Barge_In | Ogre_Errant | Spinning_Wheel | Rampart_Smasher | Spinning_Wheel | Malevolent_Noble | Realm-Cloaked_Giant | Moonlit_Scavengers |
| 69 | Golden_Egg | Wicked_Wolf | Overwhelmed_Apprentice | Enchanted_Carriage | Gilded_Goose | Once_Upon_a_Time | Burning-Yard_Trainer | Lovestruck_Beast | Seven_Dwarves | Merchant_of_the_Vale | Scalding_Cauldron | Foreboding_Fruit | Clockwork_Servant | The_Magic_Mirror | Giant_Killer |
| 70 | Didn't_Say_Please | Scalding_Cauldron | Outlaws'_Merriment | Revenge_of_Ravens | Ardenvale_Paladin | Barrow_Witches | Rimrock_Knight | Acclaimed_Contender | Maraleaf_Rider | Lovestruck_Beast | Youthful_Knight | Outflank | Wishclaw_Talisman | Smitten_Swordmaster | Drown_in_the_Loch |
| 71 | Robber_of_the_Rich | Merchant_of_the_Vale | Gilded_Goose | The_Cauldron_of_Eternity | Witch's_Oven | Scalding_Cauldron | Clockwork_Servant | Improbable_Alliance | Clackbridge_Troll | Feasting_Troll_King | Flaxen_Intruder | Barrow_Witches | Rampart_Smasher | Opt | Syr_Carah_the_Bold |
| 72 | Sundering_Stroke | Outflank | Didn't_Say_Please | The_Royal_Scions | Syr_Konrad_the_Grim | Wicked_Guardian | Clackbridge_Troll | Steelclaw_Lance | Scalding_Cauldron | Clockwork_Servant | Rally_for_the_Throne | Elite_Headhunter | Heraldic_Banner | Lost_Legion | Unexplained_Vision |
| 73 | Scalding_Cauldron | Weaselback_Redcap | Venerable_Knight | Sporecap_Spider | Belle_of_the_Brawl | Enchanted_Carriage | Harmonious_Archon | Harmonious_Archon | Redcap_Raiders | Tournament_Grounds | Witch's_Oven | Tournament_Grounds | Tuinvale_Treefolk | Scalding_Cauldron | The_Great_Henge |
| 74 | The_Circle_of_Loyalty | Rampart_Smasher | Lovestruck_Beast | Stolen_by_the_Fae | All_That_Glitters | Giant_Opportunity | Scalding_Cauldron | Claim_the_Firstborn | Thunderous_Snapper | Witch's_Oven | Sundering_Stroke | Opportunistic_Dragon | Garenbrig_Carver | Cauldron_Familiar | Blacklance_Paragon |
| 75 | Garenbrig_Carver | Flutterfox | Loch_Dragon | Opportunistic_Dragon | Idyllic_Grange | Trail_of_Crumbs | Gilded_Goose | Scalding_Cauldron | Outlaws'_Merriment | Lucky_Clover | Rankle_Master_of_Pranks | Oakhame_Ranger | The_Circle_of_Loyalty | Bonecrusher_Giant | Scalding_Cauldron |
| 76 | Deathless_Knight | Belle_of_the_Brawl | Torbran_Thane_of_Red_Fell | Scalding_Cauldron | Witch's_Vengeance | Spinning_Wheel | Feasting_Troll_King | Witch's_Oven | Oakhame_Ranger | Wishclaw_Talisman | Opportunistic_Dragon | The_Great_Henge | Oakhame_Ranger | Moonlit_Scavengers | Order_of_Midnight |
| 77 | Curious_Pair | Stormfist_Crusader | Faerie_Guidemother | Irencrag_Pyromancer | Feasting_Troll_King | Keeper_of_Fables | Lucky_Clover | Lucky_Clover | Curious_Pair | Lochmere_Serpent | Outflank | Gilded_Goose | Reaper_of_Night | Reaper_of_Night | Gilded_Goose |
| 78 | Tuinvale_Treefolk | Clockwork_Servant | Merfolk_Secretkeeper | Gingerbread_Cabin | Scorching_Dragonfire | Beanstalk_Giant | Vantress_Paladin | Charming_Prince | Golden_Egg | Wildborn_Preserver | Stolen_by_the_Fae | Wishclaw_Talisman | Maraleaf_Rider | Opportunistic_Dragon | Steelgaze_Griffin |
| 79 | Opt | Embereth_Paladin | Youthful_Knight | Sorcerer's_Broom | Knight_of_the_Keep | Irencrag_Pyromancer | Brimstone_Trebuchet | Dwarven_Mine | Giant_Killer | Weaselback_Redcap | Prized_Griffin | The_Royal_Scions | Giant_Killer | Feasting_Troll_King | Thunderous_Snapper |
| 80 | Witching_Well | Feasting_Troll_King | Unexplained_Vision | Castle_Locthwain | The_Royal_Scions | Edgewall_Innkeeper | Moonlit_Scavengers | Reave_Soul | Fireborn_Knight | Forever_Young | Piper_of_the_Swarm | Steelclaw_Lance | Sorcerer's_Broom | Malevolent_Noble | Scorching_Dragonfire |
| 81 | Oakhame_Ranger | Steelclaw_Lance | Rally_for_the_Throne | Faeburrow_Elder | Yorvo_Lord_of_Garenbrig | Witch's_Cottage | Giant_Killer | Gadwick_the_Wizened | Weaselback_Redcap | Tempting_Witch | Garenbrig_Squire | Wicked_Wolf | Scalding_Cauldron | Embercleave | Wildborn_Preserver |
| 82 | Epic_Downfall | Witch's_Vengeance | Blacklance_Paragon | Garenbrig_Squire | The_Cauldron_of_Eternity | Outmuscle | Mystical_Dispute | Foulmire_Knight | Witch's_Oven | Barrow_Witches | Maraleaf_Rider | Flutterfox | Forever_Young | Loch_Dragon | Mad_Ratter |
| 83 | Covetous_Urge | Golden_Egg | Piper_of_the_Swarm | Folio_of_Fancies | Ayara_First_of_Locthwain | Festive_Funeral | Arcanist's_Owl | Grumgully_the_Generous | Thrill_of_Possibility | Embereth_Paladin | Brazen_Borrower | Forever_Young | Wicked_Guardian | Vantress_Paladin | Reave_Soul |
| 84 | Giant_Killer | Foulmire_Knight | Silverflame_Squire | Tempting_Witch | Fervent_Champion | Vantress_Gargoyle | Covetous_Urge | Vantress_Gargoyle | Clockwork_Servant | Inspiring_Veteran | Robber_of_the_Rich | Cauldron_Familiar | Gingerbread_Cabin | Mystical_Dispute | Witch's_Vengeance |
| 85 | The_Magic_Mirror | Epic_Downfall | Wildborn_Preserver | Insatiable_Appetite | Doom_Foretold | Slaying_Fire | Thunderous_Snapper | Golden_Egg | Wildwood_Tracker | Enchanted_Carriage | The_Royal_Scions | Inspiring_Veteran | The_Royal_Scions | Unexplained_Vision | Searing_Barrage |
| 86 | Opportunistic_Dragon | Oakhame_Ranger | Wicked_Wolf | Torbran_Thane_of_Red_Fell | Irencrag_Pyromancer | Folio_of_Fancies | Outlaws'_Merriment | Fling | Brimstone_Trebuchet | Rampart_Smasher | Fireborn_Knight | Feasting_Troll_King | Sporecap_Spider | Heraldic_Banner | Foulmire_Knight |
| 87 | Harmonious_Archon | Reave_Soul | Opt | Grumgully_the_Generous | Golden_Egg | Stormfist_Crusader | Wicked_Wolf | Fires_of_Invention | Bloodhaze_Wolverine | Cauldron_Familiar | Sporecap_Spider | Golden_Egg | Locthwain_Paladin | Wildborn_Preserver | Oathsworn_Knight |
| 88 | Witch's_Oven | Lochmere_Serpent | Irencrag_Pyromancer | Wildwood_Tracker | Searing_Barrage | Sorcerer's_Broom | Ogre_Errant | The_Cauldron_of_Eternity | Worthy_Knight | Gilded_Goose | Resolute_Rider | Lovestruck_Beast | Covetous_Urge | Wicked_Guardian | Witch's_Oven |
| 89 | Piper_of_the_Swarm | Loch_Dragon | Thunderous_Snapper | Gadwick_the_Wizened | Gadwick_the_Wizened | Gingerbrute | Mystic_Sanctuary | Crystal_Slipper | Skullknocker_Ogre | Thrill_of_Possibility | Irencrag_Pyromancer | Tempting_Witch | Irencrag_Pyromancer | Thunderous_Snapper | Revenge_of_Ravens |
| 90 | Moonlit_Scavengers | Revenge_of_Ravens | Moonlit_Scavengers | Cauldron_Familiar | Joust | Syr_Alin_the_Lion's_Claw | Seven_Dwarves | Stolen_by_the_Fae | Sporecap_Spider | Golden_Egg | Silverflame_Ritual | Reaper_of_Night | Flaxen_Intruder | Robber_of_the_Rich | Feasting_Troll_King |
| 91 | Oathsworn_Knight | Mad_Ratter | Witch's_Oven | Archon_of_Absolution | Redcap_Melee | Giant's_Skewer | Raging_Redcap | Blow_Your_House_Down | Barge_In | Malevolent_Noble | Order_of_Midnight | Malevolent_Noble | Robber_of_the_Rich | Arcanist's_Owl | Mystic_Sanctuary |
| 92 | Unexplained_Vision | Syr_Konrad_the_Grim | Opportunistic_Dragon | Syr_Alin_the_Lion's_Claw | Smitten_Swordmaster | Eye_Collector | Rampart_Smasher | Gilded_Goose | Flaxen_Intruder | Wintermoor_Commander | Thunderous_Snapper | Stormfist_Crusader | Thunderous_Snapper | Wishclaw_Talisman | Corridor_Monitor |
| 93 | Vantress_Paladin | Silverflame_Ritual | Vantress_Paladin | Fae_of_Wishes | Righteousness | Drown_in_the_Loch | Mantle_of_Tides | Lochmere_Serpent | Stolen_by_the_Fae | Covetous_Urge | The_Cauldron_of_Eternity | Ardenvale_Paladin | Cauldron's_Gift | Cauldron's_Gift | Ayara_First_of_Locthwain |
| 94 | Loch_Dragon | Prized_Griffin | Covetous_Urge | Rosethorn_Halberd | Shining_Armor | Fae_of_Wishes | Wildborn_Preserver | Tournament_Grounds | Rosethorn_Halberd | Wicked_Guardian | Gadwick_the_Wizened | Prized_Griffin | Witch's_Cottage | Mystic_Sanctuary | Mistford_River_Turtle |
| 95 | Flaxen_Intruder | Bake_into_a_Pie | Syr_Konrad_the_Grim | Midnight_Clock | Revenge_of_Ravens | Opportunistic_Dragon | Lovestruck_Beast | Smitten_Swordmaster | The_Circle_of_Loyalty | Loch_Dragon | Blacklance_Paragon | Cauldron's_Gift | Torbran_Thane_of_Red_Fell | Sundering_Stroke | Once_Upon_a_Time |
| 96 | Torbran_Thane_of_Red_Fell | Lovestruck_Beast | Prized_Griffin | Belle_of_the_Brawl | Gingerbrute | Acclaimed_Contender | Redcap_Raiders | Irencrag_Feat | Elite_Headhunter | Reaper_of_Night | All_That_Glitters | Slaying_Fire | Festive_Funeral | Festive_Funeral | Bog_Naughty |
| 97 | Irencrag_Pyromancer | Seven_Dwarves | Outflank | Foreboding_Fruit | Fortifying_Provisions | Stolen_by_the_Fae | Corridor_Monitor | Revenge_of_Ravens | Fires_of_Invention | Seven_Dwarves | Arcanist's_Owl | Covetous_Urge | Sundering_Stroke | Resolute_Rider | Mantle_of_Tides |
| 98 | Maraleaf_Rider | Ardenvale_Paladin | Oakhame_Ranger | Vantress_Gargoyle | Once_Upon_a_Time | Castle_Garenbrig | Skullknocker_Ogre | Ardenvale_Tactician | Garenbrig_Squire | Stolen_by_the_Fae | Bake_into_a_Pie | Silverflame_Ritual | Giant's_Skewer | Steelgaze_Griffin | Wishful_Merfolk |
| 99 | Sporecap_Spider | Thrill_of_Possibility | Lonesome_Unicorn | Wandermare | Castle_Embereth | Rosethorn_Acolyte | Piper_of_the_Swarm | Emry_Lurker_of_the_Loch | Insatiable_Appetite | Redcap_Raiders | Folio_of_Fancies | Fervent_Champion | Elite_Headhunter | Gilded_Goose | The_Cauldron_of_Eternity |
| 100 | Mystical_Dispute | Yorvo_Lord_of_Garenbrig | Fireborn_Knight | Fell_the_Pheasant | Castle_Locthwain | Emry_Lurker_of_the_Loch | Mistford_River_Turtle | Syr_Alin_the_Lion's_Claw | Epic_Downfall | Cauldron's_Gift | Vantress_Gargoyle | Irencrag_Pyromancer | Gadwick_the_Wizened | Return_of_the_Wildspeaker | Castle_Ardenvale |
| 101 | Bake_into_a_Pie | Shining_Armor | Oathsworn_Knight | Maraleaf_Pixie | Burning-Yard_Trainer | Torbran_Thane_of_Red_Fell | Fires_of_Invention | Midnight_Clock | Lochmere_Serpent | Giant's_Skewer | Oathsworn_Knight | Arcanist's_Owl | Barrow_Witches | Locthwain_Paladin | Shambling_Suit |
| 102 | Garenbrig_Squire | Gadwick_the_Wizened | Corridor_Monitor | Return_to_Nature | Faeburrow_Elder | Syr_Elenora_the_Discerning | Witch's_Oven | Archon_of_Absolution | Gingerbread_Cabin | Wicked_Wolf | Fae_of_Wishes | Knight_of_the_Keep | Garenbrig_Squire | Giant_Killer | Castle_Locthwain |
| 103 | Syr_Konrad_the_Grim | The_Cauldron_of_Eternity | Sorcerer's_Broom | Glass_Casket | Wandermare | Wintermoor_Commander | Ferocity_of_the_Wilds | Castle_Locthwain | Fae_of_Wishes | Syr_Alin_the_Lion's_Claw | Torbran_Thane_of_Red_Fell | Wicked_Guardian | Midnight_Clock | Eye_Collector | Redcap_Melee |
| 104 | Steelgaze_Griffin | Stolen_by_the_Fae | Resolute_Rider | Tall_as_a_Beanstalk | Beloved_Princess | Memory_Theft | Elite_Headhunter | Syr_Elenora_the_Discerning | The_Cauldron_of_Eternity | Claim_the_Firstborn | Ardenvale_Paladin | Witch's_Cottage | Insatiable_Appetite | Lovestruck_Beast | Merchant_of_the_Vale |
| 105 | Arcanist's_Owl | Knight_of_the_Keep | Once_Upon_a_Time | Trapped_in_the_Tower | Fae_of_Wishes | Glass_Casket | Weaselback_Redcap | Worthy_Knight | Savvy_Hunter | Festive_Funeral | Epic_Downfall | Syr_Carah_the_Bold | Gingerbrute | Corridor_Monitor | Sorcerer's_Broom |
| 106 | Savvy_Hunter | Barge_In | Mystical_Dispute | Wishclaw_Talisman | Keeper_of_Fables | Kenrith's_Transformation | Witch's_Vengeance | Escape_to_the_Wilds | Acclaimed_Contender | Yorvo_Lord_of_Garenbrig | Lochmere_Serpent | Sundering_Stroke | Stolen_by_the_Fae | Irencrag_Pyromancer | Outlaws'_Merriment |
| 107 | Blacklance_Paragon | Ayara_First_of_Locthwain | Steelgaze_Griffin | Castle_Ardenvale | Jousting_Dummy | Steelclaw_Lance | Embereth_Paladin | Hushbringer | Dwarven_Mine | Return_of_the_Wildspeaker | Midnight_Clock | Giant's_Skewer | Wildwood_Tracker | Deathless_Knight | Maraleaf_Pixie |
| 108 | Order_of_Midnight | Wintermoor_Commander | Henge_Walker | Escape_to_the_Wilds | Shambling_Suit | Doom_Foretold | Fireborn_Knight | Castle_Ardenvale | Faeburrow_Elder | Barge_In | Insatiable_Appetite | Yorvo_Lord_of_Garenbrig | Fae_of_Wishes | Witch's_Cottage | Beanstalk_Giant |
| 109 | Slaying_Fire | Midnight_Clock | Return_of_the_Wildspeaker | Hypnotic_Sprite | True_Love's_Kiss | Castle_Vantress | Oathsworn_Knight | Return_of_the_Wildspeaker | Embereth_Paladin | Skullknocker_Ogre | Wildwood_Tracker | Return_of_the_Wildspeaker | Rosethorn_Halberd | Memory_Theft | Worthy_Knight |
| 110 | Gingerbread_Cabin | Return_of_the_Wildspeaker | The_Cauldron_of_Eternity | Henge_Walker | Emry_Lurker_of_the_Loch | Garenbrig_Paladin | Epic_Downfall | Trapped_in_the_Tower | Ayara_First_of_Locthwain | Vantress_Gargoyle | Rosethorn_Halberd | Shining_Armor | Vantress_Gargoyle | Elite_Headhunter | Return_of_the_Wildspeaker |
| 111 | Acclaimed_Contender | Castle_Locthwain | Gingerbrute | Forever_Young | Henge_Walker | Lash_of_Thorns | Blacklance_Paragon | Gingerbrute | Gingerbrute | Lash_of_Thorns | Gingerbread_Cabin | All_That_Glitters | Return_to_Nature | Shambling_Suit | Archon_of_Absolution |
| 112 | Foulmire_Knight | Fires_of_Invention | Inquisitive_Puppet | Linden_the_Steadfast_Queen | Brimstone_Trebuchet | Hushbringer | Once_Upon_a_Time | Venerable_Knight | Oathsworn_Knight | Folio_of_Fancies | Revenge_of_Ravens | Festive_Funeral | Fell_the_Pheasant | Mistford_River_Turtle | Keeper_of_Fables |
| 113 | Outlaws'_Merriment | Smitten_Swordmaster | Silverflame_Ritual | Wolf's_Quarry | Crashing_Drawbridge | Prophet_of_the_Peak | Wishful_Merfolk | Syr_Faren_the_Hengehammer | Fling | Archon_of_Absolution | Sorcerer's_Broom | Gadwick_the_Wizened | Lash_of_Thorns | Wishful_Merfolk | Shinechaser |
| 114 | Sorcerer's_Broom | Idyllic_Grange | Ayara_First_of_Locthwain | Scorching_Dragonfire | Bog_Naughty | Scorching_Dragonfire | Barge_In | Faerie_Vandal | Tall_as_a_Beanstalk | Glass_Casket | Gingerbrute | Sorcerer's_Broom | Folio_of_Fancies | Barrow_Witches | Glass_Casket |
| 115 | Faeburrow_Elder | Jousting_Dummy | Righteousness | Gingerbrute | Tournament_Grounds | Hypnotic_Sprite | Bake_into_a_Pie | Turn_into_a_Pumpkin | Syr_Konrad_the_Grim | Witch's_Cottage | Savvy_Hunter | Folio_of_Fancies | Tall_as_a_Beanstalk | Giant's_Skewer | Trapped_in_the_Tower |
| 116 | Ayara_First_of_Locthwain | Righteousness | Sorcerous_Spyglass | Syr_Carah_the_Bold | Embereth_Shieldbreaker | Curious_Pair | Fling | Fae_of_Wishes | Blacklance_Paragon | Fae_of_Wishes | Idyllic_Grange | Once_Upon_a_Time | Memory_Theft | Wicked_Wolf | Gingerbrute |
| 117 | Scorching_Dragonfire | Wildborn_Preserver | Epic_Downfall | Animating_Faerie | Deathless_Knight | Faerie_Vandal | Dwarven_Mine | Bog_Naughty | Emry_Lurker_of_the_Loch | Linden_the_Steadfast_Queen | Fell_the_Pheasant | Gingerbrute | Eye_Collector | Yorvo_Lord_of_Garenbrig | Charming_Prince |
| 118 | Mistford_River_Turtle | Crystal_Slipper | Slaying_Fire | Charming_Prince | Lochmere_Serpent | Once_and_Future | Worthy_Knight | Sorcerer's_Broom | Claim_the_Firstborn | Bloodhaze_Wolverine | True_Love's_Kiss | Scorching_Dragonfire | Emry_Lurker_of_the_Loch | Sorcerer's_Broom | Syr_Alin_the_Lion's_Claw |
| 119 | Rosethorn_Halberd | All_That_Glitters | Crashing_Drawbridge | Searing_Barrage | Bartered_Cow | Outlaws'_Merriment | Syr_Konrad_the_Grim | Castle_Garenbrig | Fell_the_Pheasant | Fling | Righteousness | Stolen_by_the_Fae | Worthy_Knight | Lash_of_Thorns | Yorvo_Lord_of_Garenbrig |
| 120 | Reave_Soul | Arcanist's_Owl | Mystic_Sanctuary | Worthy_Knight | Shinechaser | Archon_of_Absolution | Yorvo_Lord_of_Garenbrig | Jousting_Dummy | Crystal_Slipper | Venerable_Knight | Return_to_Nature | Righteousness | Maraleaf_Pixie | Charming_Prince | Prophet_of_the_Peak |
| 121 | Witch's_Vengeance | Claim_the_Firstborn | Ardenvale_Paladin | Reaper_of_Night | Elite_Headhunter | Specter's_Shriek | Shambling_Suit | Once_Upon_a_Time | Return_to_Nature | Doom_Foretold | Castle_Locthwain | Shambling_Suit | Grumgully_the_Generous | Specter's_Shriek | Dance_of_the_Manse |
| 122 | The_Cauldron_of_Eternity | Redcap_Raiders | Revenge_of_Ravens | Resolute_Rider | Edgewall_Innkeeper | Charming_Prince | Claim_the_Firstborn | Shambling_Suit | Bake_into_a_Pie | Jousting_Dummy | Slaying_Fire | Vantress_Gargoyle | Wolf's_Quarry | Gingerbrute | Foreboding_Fruit |
| 123 | Drown_in_the_Loch | Skullknocker_Ogre | Wishclaw_Talisman | Slaying_Fire | Oakhame_Adversary | Turn_into_a_Pumpkin | Castle_Locthwain | Hypnotic_Sprite | Foulmire_Knight | Castle_Ardenvale | Bartered_Cow | Jousting_Dummy | Faeburrow_Elder | Glass_Casket | Embereth_Shieldbreaker |
| 124 | Corridor_Monitor | Ferocity_of_the_Wilds | Castle_Locthwain | Mysterious_Pathlighter | Folio_of_Fancies | Ardenvale_Tactician | Crystal_Slipper | Glass_Casket | Wishclaw_Talisman | Fires_of_Invention | Fortifying_Provisions | Idyllic_Grange | Syr_Alin_the_Lion's_Claw | Prophet_of_the_Peak | Fierce_Witchstalker |
| 125 | Mystic_Sanctuary | Gingerbrute | Shining_Armor | Castle_Vantress | Covetous_Urge | Fervent_Champion | Irencrag_Feat | Henge_Walker | Castle_Ardenvale | Midnight_Clock | Grumgully_the_Generous | Lash_of_Thorns | Specter's_Shriek | Mantle_of_Tides | Oakhame_Adversary |
| 126 | Grumgully_the_Generous | Fling | Mantle_of_Tides | Outlaws'_Merriment | Outmuscle | Syr_Carah_the_Bold | Hushbringer | Beanstalk_Giant | Syr_Alin_the_Lion's_Claw | Ardenvale_Tactician | Knight_of_the_Keep | True_Love's_Kiss | Prophet_of_the_Peak | Crashing_Drawbridge | Crashing_Drawbridge |
| 127 | Castle_Locthwain | Wishclaw_Talisman | Fortifying_Provisions | Shambling_Suit | Beanstalk_Giant | Castle_Embereth | Order_of_Midnight | Keeper_of_Fables | Castle_Locthwain | Dwarven_Mine | Crashing_Drawbridge | Castle_Embereth | Charming_Prince | Savvy_Hunter | Inquisitive_Puppet |
| 128 | Linden_the_Steadfast_Queen | Folio_of_Fancies | Jousting_Dummy | Smitten_Swordmaster | Stolen_by_the_Fae | Henge_Walker | Charming_Prince | Outmuscle | Gadwick_the_Wizened | Ferocity_of_the_Wilds | Tall_as_a_Beanstalk | Fae_of_Wishes | Shambling_Suit | Worthy_Knight | Belle_of_the_Brawl |
| 129 | Wildwood_Tracker | Once_Upon_a_Time | Mistford_River_Turtle | Shepherd_of_the_Flock | Return_of_the_Wildspeaker | Crashing_Drawbridge | Drown_in_the_Loch | Animating_Faerie | Wolf's_Quarry | Sorcerer's_Broom | Beloved_Princess | Fortifying_Provisions | Stormfist_Crusader | Hushbringer | Outmuscle |
| 130 | Insatiable_Appetite | Witch's_Oven | Doom_Foretold | Fervent_Champion | Sorcerer's_Broom | Charmed_Sleep | Return_of_the_Wildspeaker | Ayara_First_of_Locthwain | Revenge_of_Ravens | Gingerbrute | Ayara_First_of_Locthwain | Wildborn_Preserver | Drown_in_the_Loch | Stormfist_Crusader | Thrill_of_Possibility |
| 131 | Revenge_of_Ravens | Bloodhaze_Wolverine | Bake_into_a_Pie | Emry_Lurker_of_the_Loch | Syr_Elenora_the_Discerning | Trapped_in_the_Tower | Linden_the_Steadfast_Queen | Crashing_Drawbridge | Midnight_Clock | Emry_Lurker_of_the_Loch | Shambling_Suit | Savvy_Hunter | Wandermare | Acclaimed_Contender | Edgewall_Innkeeper |
| 132 | Gingerbrute | Fortifying_Provisions | Witch's_Vengeance | Covetous_Urge | Hypnotic_Sprite | Jousting_Dummy | Gingerbrute | Tome_Raider | The_Magic_Mirror | Once_Upon_a_Time | Maraleaf_Pixie | Joust | Archon_of_Absolution | Dance_of_the_Manse | Fireborn_Knight |
| 133 | Return_to_Nature | Doom_Foretold | Locthwain_Gargoyle | Charmed_Sleep | Prophet_of_the_Peak | Linden_the_Steadfast_Queen | Crashing_Drawbridge | Yorvo_Lord_of_Garenbrig | Irencrag_Feat | Eye_Collector | Jousting_Dummy | Eye_Collector | Scorching_Dragonfire | Beanstalk_Giant | Forever_Young |
| 134 | Wishful_Merfolk | Fae_of_Wishes | Syr_Carah_the_Bold | Lost_Legion | Syr_Faren_the_Hengehammer | Animating_Faerie | Grumgully_the_Generous | Charmed_Sleep | Reave_Soul | Gadwick_the_Wizened | Prophet_of_the_Peak | Crashing_Drawbridge | Escape_to_the_Wilds | Once_Upon_a_Time | Henge_Walker |
| 135 | Archon_of_Absolution | Dwarven_Mine | Drown_in_the_Loch | Turn_into_a_Pumpkin | Wishclaw_Talisman | Gingerbread_Cabin | Stormfist_Crusader | Youthful_Knight | Crashing_Drawbridge | Charming_Prince | Shining_Armor | Specter's_Shriek | The_Magic_Mirror | Henge_Walker | Brimstone_Trebuchet |
| 136 | Shambling_Suit | Crashing_Drawbridge | Prophet_of_the_Peak | Crashing_Drawbridge | Merchant_of_the_Vale | Shambling_Suit | Revenge_of_Ravens | Linden_the_Steadfast_Queen | Steelclaw_Lance | Crystal_Slipper | Inquisitive_Puppet | Searing_Barrage | Crashing_Drawbridge | Doom_Foretold | Castle_Embereth |
| 137 | Charming_Prince | Emry_Lurker_of_the_Loch | Beloved_Princess | Malevolent_Noble | The_Magic_Mirror | Tuinvale_Treefolk | Reave_Soul | Wintermoor_Commander | Blow_Your_House_Down | Trapped_in_the_Tower | Wolf's_Quarry | Castle_Vantress | Outlaws'_Merriment | Improbable_Alliance | Sorcerous_Spyglass |
| 138 | Wishclaw_Talisman | Sorcerer's_Broom | Improbable_Alliance | Wicked_Guardian | Lost_Legion | Embereth_Shieldbreaker | Acclaimed_Contender | Sage_of_the_Falls | Shambling_Suit | Improbable_Alliance | Escape_to_the_Wilds | Memory_Theft | Henge_Walker | Outlaws'_Merriment | Signpost_Scarecrow |
| 139 | Fell_the_Pheasant | True_Love's_Kiss | True_Love's_Kiss | Giant's_Skewer | Inquisitive_Puppet | Worthy_Knight | Sorcerer's_Broom | Fierce_Witchstalker | Stormfist_Crusader | Specter's_Shriek | Hypnotic_Sprite | Henge_Walker | Inquisitive_Puppet | Castle_Garenbrig | Fervent_Champion |
| 140 | Tall_as_a_Beanstalk | Blow_Your_House_Down | Idyllic_Grange | Faerie_Vandal | Vantress_Gargoyle | Inquisitive_Puppet | Castle_Ardenvale | Lost_Legion | Vantress_Gargoyle | Blow_Your_House_Down | Fervent_Champion | Prophet_of_the_Peak | Glass_Casket | Inquisitive_Puppet | Mysterious_Pathlighter |
| 141 | Glass_Casket | Vantress_Gargoyle | Bartered_Cow | Cauldron's_Gift | Midnight_Clock | Merfolk_Secretkeeper | Blow_Your_House_Down | Malevolent_Noble | Improbable_Alliance | Memory_Theft | Emry_Lurker_of_the_Loch | Embereth_Shieldbreaker | Sorcerous_Spyglass | Fervent_Champion | Jousting_Dummy |
| 142 | Prophet_of_the_Peak | Lost_Legion | Wishful_Merfolk | Joust | Castle_Vantress | The_Magic_Mirror | Prophet_of_the_Peak | Mirrormade | Witch's_Vengeance | The_Magic_Mirror | Henge_Walker | Beloved_Princess | Steelclaw_Lance | Sorcerous_Spyglass | Kenrith's_Transformation |
| 143 | Searing_Barrage | Gilded_Goose | Sundering_Stroke | Syr_Elenora_the_Discerning | Ogre_Errant | Rampart_Smasher | Escape_to_the_Wilds | Prophet_of_the_Peak | Sorcerer's_Broom | Savvy_Hunter | Sorcerous_Spyglass | Burning-Yard_Trainer | Doom_Foretold | Castle_Ardenvale | Smitten_Swordmaster |
| 144 | Wolf's_Quarry | Bartered_Cow | Rampart_Smasher | Prophet_of_the_Peak | Locthwain_Gargoyle | Sporecap_Spider | The_Cauldron_of_Eternity | Weapon_Rack | Henge_Walker | Irencrag_Feat | Foulmire_Knight | Inquisitive_Puppet | Slaying_Fire | Jousting_Dummy | Reaper_of_Night |
| 145 | Escape_to_the_Wilds | Faeburrow_Elder | Knight_of_the_Keep | Locthwain_Paladin | Locthwain_Paladin | Maraleaf_Rider | Archon_of_Absolution | Folio_of_Fancies | Glass_Casket | Hushbringer | Happily_Ever_After | Bartered_Cow | Acclaimed_Contender | Locthwain_Gargoyle | Ardenvale_Tactician |
| 146 | Improbable_Alliance | Beloved_Princess | Happily_Ever_After | Witch's_Cottage | Happily_Ever_After | Castle_Ardenvale | Inquisitive_Puppet | Opt | Order_of_Midnight | Shambling_Suit | Witch's_Vengeance | Rimrock_Knight | Syr_Elenora_the_Discerning | Keeper_of_Fables | Lost_Legion |
| 147 | Worthy_Knight | Improbable_Alliance | Yorvo_Lord_of_Garenbrig | Castle_Embereth | Fierce_Witchstalker | Shepherd_of_the_Flock | Sorcerous_Spyglass | Inquisitive_Puppet | Bog_Naughty | Oakhame_Ranger | The_Magic_Mirror | Syr_Elenora_the_Discerning | Syr_Carah_the_Bold | Maraleaf_Pixie | Hushbringer |
| 148 | Wandermare | Inquisitive_Puppet | Order_of_Midnight | Festive_Funeral | Castle_Garenbrig | Faeburrow_Elder | Henge_Walker | Forever_Young | Inspiring_Veteran | Castle_Vantress | Scorching_Dragonfire | Brimstone_Trebuchet | Castle_Ardenvale | Scorching_Dragonfire | Stormfist_Crusader |
| 149 | Bog_Naughty | Henge_Walker | Redcap_Melee | Tome_Raider | Savvy_Hunter | Garenbrig_Carver | Resolute_Rider | Barrow_Witches | Archon_of_Absolution | Grumgully_the_Generous | Animating_Faerie | The_Magic_Mirror | Fervent_Champion | Signpost_Scarecrow | Castle_Garenbrig |
| 150 | Castle_Embereth | Weapon_Rack | Weapon_Rack | The_Magic_Mirror | Steelclaw_Lance | Mysterious_Pathlighter | Dance_of_the_Manse | Mysterious_Pathlighter | Faerie_Vandal | Crashing_Drawbridge | Inspiring_Veteran | Faeburrow_Elder | Animating_Faerie | Trail_of_Crumbs | Acclaimed_Contender |
| 151 | Mantle_of_Tides | Syr_Elenora_the_Discerning | Foulmire_Knight | Redcap_Melee | Forever_Young | Rimrock_Knight | Beanstalk_Giant | Oakhame_Adversary | Maraleaf_Pixie | Shepherd_of_the_Flock | Mirrormade | Castle_Garenbrig | Searing_Barrage | Edgewall_Innkeeper | Wishclaw_Talisman |
| 152 | Mad_Ratter | Hypnotic_Sprite | Signpost_Scarecrow | Faerie_Guidemother | Sorcerous_Spyglass | Sage_of_the_Falls | Steelclaw_Lance | Frogify | Castle_Vantress | Henge_Walker | Weapon_Rack | Weapon_Rack | Signpost_Scarecrow | Oakhame_Adversary | Locthwain_Gargoyle |
| 153 | Belle_of_the_Brawl | Shambling_Suit | Edgewall_Innkeeper | Sorcerous_Spyglass | Trail_of_Crumbs | Overwhelmed_Apprentice | Ayara_First_of_Locthwain | Foreboding_Fruit | Wandermare | Fierce_Witchstalker | Castle_Embereth | Signpost_Scarecrow | Hypnotic_Sprite | Syr_Alin_the_Lion's_Claw | Bloodhaze_Wolverine |
| 154 | Syr_Carah_the_Bold | The_Magic_Mirror | Beanstalk_Giant | Inquisitive_Puppet | Dance_of_the_Manse | Frogify | Jousting_Dummy | Locthwain_Paladin | Inquisitive_Puppet | Inquisitive_Puppet | Wishclaw_Talisman | Drown_in_the_Loch | Jousting_Dummy | Weapon_Rack | Once_and_Future |
| 155 | Elite_Headhunter | Deafening_Silence | Keeper_of_Fables | Signpost_Scarecrow | Rimrock_Knight | Sorcerous_Spyglass | Syr_Alin_the_Lion's_Claw | Castle_Vantress | Signpost_Scarecrow | Youthful_Knight | Doom_Foretold | Beanstalk_Giant | Locthwain_Gargoyle | Archon_of_Absolution | Cauldron_Familiar |
| 156 | Signpost_Scarecrow | Sorcerous_Spyglass | Faeburrow_Elder | Acclaimed_Contender | Giant's_Skewer | Flaxen_Intruder | Bog_Naughty | Shepherd_of_the_Flock | Charming_Prince | Prophet_of_the_Peak | Signpost_Scarecrow | Sorcerous_Spyglass | Wintermoor_Commander | Shinechaser | Flutterfox |
| 157 | Hushbringer | Happily_Ever_After | Maraleaf_Pixie | Ardenvale_Tactician | Animating_Faerie | Tournament_Grounds | Edgewall_Innkeeper | Signpost_Scarecrow | Trapped_in_the_Tower | Sorcerous_Spyglass | Syr_Konrad_the_Grim | Hypnotic_Sprite | Hushbringer | Redcap_Melee | Weapon_Rack |
| 158 | Crashing_Drawbridge | Irencrag_Feat | Deafening_Silence | Barrow_Witches | Deafening_Silence | Oakhame_Ranger | Maraleaf_Pixie | Resolute_Rider | Jousting_Dummy | Beanstalk_Giant | Stormfist_Crusader | Dance_of_the_Manse | Castle_Embereth | Syr_Carah_the_Bold | Savvy_Hunter |
| 159 | Henge_Walker | Prophet_of_the_Peak | Mad_Ratter | Queen_of_Ice | Rosethorn_Acolyte | Queen_of_Ice | Inspiring_Veteran | Edgewall_Innkeeper | Prophet_of_the_Peak | Mirrormade | Locthwain_Gargoyle | Edgewall_Innkeeper | Castle_Vantress | Searing_Barrage | Shepherd_of_the_Flock |
| 160 | Inquisitive_Puppet | Grumgully_the_Generous | Castle_Garenbrig | Doom_Foretold | Mirrormade | So_Tiny | Weapon_Rack | Sorcerous_Spyglass | Syr_Elenora_the_Discerning | Faerie_Vandal | Bog_Naughty | Giant_Opportunity | Improbable_Alliance | Steelclaw_Lance | Joust |
| 161 | Castle_Ardenvale | Bog_Naughty | Reave_Soul | Fireborn_Knight | Charmed_Sleep | Weapon_Rack | Signpost_Scarecrow | Doom_Foretold | Linden_the_Steadfast_Queen | Weapon_Rack | Searing_Barrage | Syr_Faren_the_Hengehammer | Linden_the_Steadfast_Queen | Mad_Ratter | Trail_of_Crumbs |
| 162 | Resolute_Rider | Castle_Vantress | Fervent_Champion | Jousting_Dummy | Stormfist_Crusader | Inspiring_Veteran | Locthwain_Gargoyle | Witching_Well | Sorcerous_Spyglass | Escape_to_the_Wilds | Castle_Vantress | Redcap_Melee | Mysterious_Pathlighter | Roving_Keep | Festive_Funeral |
| 163 | Fervent_Champion | Signpost_Scarecrow | Roving_Keep | Frogify | Rampart_Smasher | Thunderous_Snapper | Roving_Keep | Righteousness | Hushbringer | Faeburrow_Elder | Faerie_Vandal | Locthwain_Gargoyle | Shepherd_of_the_Flock | Slaying_Fire | Tempting_Witch |
| 164 | Jousting_Dummy | Deathless_Knight | Giant_Opportunity | Locthwain_Gargoyle | Raging_Redcap | Signpost_Scarecrow | Outmuscle | The_Magic_Mirror | Doom_Foretold | Drown_in_the_Loch | Dance_of_the_Manse | Happily_Ever_After | Weapon_Rack | Outmuscle | Burning-Yard_Trainer |
| 165 | Shinechaser | Castle_Garenbrig | Scorching_Dragonfire | Embereth_Shieldbreaker | Witch's_Cottage | Searing_Barrage | Ardenvale_Tactician | Wicked_Guardian | Mirrormade | Syr_Elenora_the_Discerning | Syr_Elenora_the_Discerning | Mirrormade | Trapped_in_the_Tower | Shepherd_of_the_Flock | Rimrock_Knight |
| 166 | Sorcerous_Spyglass | Edgewall_Innkeeper | Syr_Faren_the_Hengehammer | Mad_Ratter | Faerie_Vandal | Into_the_Story | Faeburrow_Elder | Into_the_Story | Drown_in_the_Loch | Keeper_of_Fables | Reave_Soul | Shinechaser | Roving_Keep | Trapped_in_the_Tower | Elite_Headhunter |
| 167 | Syr_Alin_the_Lion's_Claw | Foreboding_Fruit | Wandermare | Overwhelmed_Apprentice | Signpost_Scarecrow | Tome_Raider | Belle_of_the_Brawl | Didn't_Say_Please | Arcanist's_Owl | Hypnotic_Sprite | Shinechaser | Oakhame_Adversary | Dance_of_the_Manse | Faeburrow_Elder | Faeburrow_Elder |
| 168 | Fires_of_Invention | Escape_to_the_Wilds | Savvy_Hunter | Sage_of_the_Falls | Turn_into_a_Pumpkin | Locthwain_Gargoyle | Oakhame_Adversary | Faerie_Guidemother | Weapon_Rack | Roving_Keep | Turn_into_a_Pumpkin | Deafening_Silence | Fires_of_Invention | Syr_Faren_the_Hengehammer | Giant's_Skewer |
| 169 | Trapped_in_the_Tower | Wandermare | Joust | Weapon_Rack | Roving_Keep | Witching_Well | Shinechaser | Reaper_of_Night | Animating_Faerie | Syr_Faren_the_Hengehammer | Wintermoor_Commander | Emry_Lurker_of_the_Loch | Frogify | Fierce_Witchstalker | Cauldron's_Gift |
| 170 | Weapon_Rack | Forever_Young | Oakhame_Adversary | Merchant_of_the_Vale | Barrow_Witches | Rosethorn_Halberd | Keeper_of_Fables | Specter's_Shriek | Mysterious_Pathlighter | Mysterious_Pathlighter | Belle_of_the_Brawl | Fierce_Witchstalker | Mirrormade | Wintermoor_Commander | Rosethorn_Acolyte |
| 171 | Forever_Young | Locthwain_Paladin | Castle_Embereth | Flutterfox | Tempting_Witch | Didn't_Say_Please | Trail_of_Crumbs | Tempting_Witch | Folio_of_Fancies | Edgewall_Innkeeper | Deafening_Silence | Wandermare | Tournament_Grounds | Oakhame_Ranger | Wicked_Guardian |
| 172 | Mysterious_Pathlighter | Mirrormade | Burning-Yard_Trainer | Stormfist_Crusader | Giant_Opportunity | Fires_of_Invention | Tournament_Grounds | Rosethorn_Acolyte | Belle_of_the_Brawl | Castle_Garenbrig | Embereth_Shieldbreaker | Animating_Faerie | Mad_Ratter | Grumgully_the_Generous | Fires_of_Invention |
| 173 | Roving_Keep | Dance_of_the_Manse | Deathless_Knight | Merfolk_Secretkeeper | Curious_Pair | Improbable_Alliance | Wishclaw_Talisman | Trail_of_Crumbs | Sage_of_the_Falls | Outmuscle | Syr_Carah_the_Bold | Weaselback_Redcap | Faerie_Vandal | Castle_Embereth | Witch's_Cottage |
| 174 | Foreboding_Fruit | Barrow_Witches | Tournament_Grounds | Silverflame_Squire | Embereth_Paladin | Redcap_Melee | Glass_Casket | Overwhelmed_Apprentice | Covetous_Urge | Signpost_Scarecrow | Improbable_Alliance | Outmuscle | Joust | Kenrith's_Transformation | Doom_Foretold |
| 175 | Smitten_Swordmaster | Locthwain_Gargoyle | Flaxen_Intruder | Lash_of_Thorns | Tome_Raider | Venerable_Knight | Doom_Foretold | Run_Away_Together | Hypnotic_Sprite | Wandermare | Joust | Mad_Ratter | Happily_Ever_After | Tournament_Grounds | Ferocity_of_the_Wilds |
| 176 | Cauldron_Familiar | Giant_Opportunity | Steelclaw_Lance | Dance_of_the_Manse | Reaper_of_Night | Burning-Yard_Trainer | Deathless_Knight | Lonesome_Unicorn | Turn_into_a_Pumpkin | Locthwain_Gargoyle | Roving_Keep | Midnight_Clock | Turn_into_a_Pumpkin | Linden_the_Steadfast_Queen | Roving_Keep |
| 177 | Locthwain_Gargoyle | Shinechaser | Escape_to_the_Wilds | Rimrock_Knight | Loch_Dragon | Joust | Fierce_Witchstalker | Queen_of_Ice | Locthwain_Gargoyle | Oakhame_Adversary | Drown_in_the_Loch | Grumgully_the_Generous | Inspiring_Veteran | Escape_to_the_Wilds | Garenbrig_Paladin |
| 178 | Dance_of_the_Manse | Oakhame_Adversary | Inspiring_Veteran | Lonesome_Unicorn | Frogify | Brimstone_Trebuchet | Giant_Opportunity | Faeburrow_Elder | Tournament_Grounds | Dance_of_the_Manse | Merfolk_Secretkeeper | Raging_Redcap | Mystical_Dispute | Inspiring_Veteran | Steelclaw_Lance |
| 179 | Shepherd_of_the_Flock | Turn_into_a_Pumpkin | Stormfist_Crusader | Hushbringer | Cauldron's_Gift | Escape_to_the_Wilds | Mysterious_Pathlighter | Roving_Keep | Ardenvale_Tactician | Faerie_Guidemother | Steelclaw_Lance | Roving_Keep | Faerie_Guidemother | Giant_Opportunity | Faerie_Guidemother |
| 180 | Ardenvale_Tactician | Roving_Keep | Grumgully_the_Generous | Mirrormade | Weapon_Rack | Opt | Foulmire_Knight | Locthwain_Gargoyle | Tempting_Witch | Lonesome_Unicorn | Redcap_Melee | Embereth_Paladin | Merfolk_Secretkeeper | Rosethorn_Acolyte | Memory_Theft |
| 181 | Joust | Cauldron_Familiar | Kenrith's_Transformation | Arcanist's_Owl | Weaselback_Redcap | Garenbrig_Squire | Forever_Young | Giant's_Skewer | Wintermoor_Commander | All_That_Glitters | Tournament_Grounds | Kenrith's_Transformation | Into_the_Story | Flaxen_Intruder | Grumgully_the_Generous |
| 182 | Tempting_Witch | Beanstalk_Giant | Wintermoor_Commander | So_Tiny | Malevolent_Noble | Mad_Ratter | Savvy_Hunter | Kenrith's_Transformation | Roving_Keep | Animating_Faerie | Smitten_Swordmaster | Sage_of_the_Falls | Moonlit_Scavengers | Embereth_Shieldbreaker | Raging_Redcap |
| 183 | Stormfist_Crusader | Maraleaf_Pixie | Fires_of_Invention | Run_Away_Together | Into_the_Story | Maraleaf_Pixie | Trapped_in_the_Tower | Deathless_Knight | Shinechaser | Sage_of_the_Falls | Mad_Ratter | Fires_of_Invention | Irencrag_Feat | Joust | Syr_Faren_the_Hengehammer |
| 184 | Merchant_of_the_Vale | Cauldron's_Gift | Trail_of_Crumbs | Burning-Yard_Trainer | Crystal_Slipper | Insatiable_Appetite | Castle_Garenbrig | Mystical_Dispute | Frogify | Ardenvale_Paladin | Merchant_of_the_Vale | Keeper_of_Fables | Charmed_Sleep | Irencrag_Feat | Eye_Collector |
| 185 | Steelclaw_Lance | Tempting_Witch | Fierce_Witchstalker | Youthful_Knight | Foreboding_Fruit | Thrill_of_Possibility | Wandermare | Thunderous_Snapper | Venerable_Knight | Happily_Ever_After | Fires_of_Invention | Ogre_Errant | Fireborn_Knight | Wandermare | All_That_Glitters |
| 186 | Redcap_Melee | Savvy_Hunter | Embereth_Shieldbreaker | Roving_Keep | Escape_to_the_Wilds | Moonlit_Scavengers | Smitten_Swordmaster | Outflank | Mystical_Dispute | Thunderous_Snapper | Brimstone_Trebuchet | Garenbrig_Paladin | Ardenvale_Tactician | Venerable_Knight | Wintermoor_Commander |
| 187 | Giant's_Skewer | Drown_in_the_Loch | Searing_Barrage | Improbable_Alliance | Tuinvale_Treefolk | Fell_the_Pheasant | Kenrith's_Transformation | Silverflame_Ritual | Tome_Raider | Once_and_Future | Giant's_Skewer | Frogify | Queen_of_Ice | Happily_Ever_After | Claim_the_Firstborn |
| 188 | Doom_Foretold | Faerie_Vandal | Smitten_Swordmaster | Witching_Well | Wicked_Guardian | Grumgully_the_Generous | Once_and_Future | Curious_Pair | Queen_of_Ice | Righteousness | Sage_of_the_Falls | Maraleaf_Pixie | Embereth_Shieldbreaker | Fires_of_Invention | Sporecap_Spider |
| 189 | Wintermoor_Commander | Giant's_Skewer | Bog_Naughty | Drown_in_the_Loch | Cauldron_Familiar | Return_to_Nature | Righteousness | Dance_of_the_Manse | Smitten_Swordmaster | Giant_Opportunity | Into_the_Story | Once_and_Future | Witching_Well | Righteousness | Escape_to_the_Wilds |
| 190 | Irencrag_Feat | Queen_of_Ice | Belle_of_the_Brawl | Mystical_Dispute | Flaxen_Intruder | Irencrag_Feat | Cauldron_Familiar | Wishclaw_Talisman | Shepherd_of_the_Flock | Rally_for_the_Throne | Rimrock_Knight | Flaxen_Intruder | Tome_Raider | Garenbrig_Paladin | Specter's_Shriek |
| 191 | Faerie_Guidemother | Sage_of_the_Falls | Outmuscle | Tournament_Grounds | Mad_Ratter | Roving_Keep | Oakhame_Ranger | So_Tiny | Charmed_Sleep | Mystical_Dispute | Run_Away_Together | Escape_to_the_Wilds | Venerable_Knight | Merchant_of_the_Vale | Wandermare |
| 192 | Venerable_Knight | Flaxen_Intruder | Giant's_Skewer | Memory_Theft | Queen_of_Ice | Tall_as_a_Beanstalk | Rally_for_the_Throne | Giant_Opportunity | Dance_of_the_Manse | Trail_of_Crumbs | Cauldron_Familiar | Turn_into_a_Pumpkin | Didn't_Say_Please | Once_and_Future | Inspiring_Veteran |
| 193 | Cauldron's_Gift | Keeper_of_Fables | Rimrock_Knight | Unexplained_Vision | Once_and_Future | Mirrormade | Syr_Faren_the_Hengehammer | Flutterfox | Giant's_Skewer | Maraleaf_Pixie | Charmed_Sleep | Skullknocker_Ogre | Brimstone_Trebuchet | Gingerbread_Cabin | Curious_Pair |
| 194 | Embereth_Shieldbreaker | Witch's_Cottage | Merchant_of_the_Vale | Into_the_Story | Improbable_Alliance | All_That_Glitters | Flaxen_Intruder | All_That_Glitters | Happily_Ever_After | Outflank | Reaper_of_Night | Into_the_Story | Sage_of_the_Falls | Faerie_Guidemother | Malevolent_Noble |
| 195 | Reaper_of_Night | Kenrith's_Transformation | Cauldron_Familiar | Elite_Headhunter | Garenbrig_Paladin | Fireborn_Knight | Venerable_Knight | Drown_in_the_Loch | Forever_Young | Turn_into_a_Pumpkin | Tome_Raider | Trail_of_Crumbs | All_That_Glitters | Return_to_Nature | Crystal_Slipper |
| 196 | Burning-Yard_Trainer | Festive_Funeral | Forever_Young | Ferocity_of_the_Wilds | Kenrith's_Transformation | Wolf's_Quarry | Foreboding_Fruit | Savvy_Hunter | Merfolk_Secretkeeper | Knight_of_the_Keep | Queen_of_Ice | Merfolk_Secretkeeper | Overwhelmed_Apprentice | Ardenvale_Tactician | Giant_Opportunity |
| 197 | Fireborn_Knight | Fierce_Witchstalker | Tuinvale_Treefolk | Venerable_Knight | Maraleaf_Rider | Wildwood_Tracker | Wintermoor_Commander | Cauldron_Familiar | Run_Away_Together | Frogify | Tempting_Witch | Queen_of_Ice | Shinechaser | Tuinvale_Treefolk | Skullknocker_Ogre |
| 198 | All_That_Glitters | Into_the_Story | Brimstone_Trebuchet | Righteousness | Merfolk_Secretkeeper | Youthful_Knight | Rosethorn_Acolyte | Festive_Funeral | Reaper_of_Night | Garenbrig_Paladin | Frogify | Merchant_of_the_Vale | Unexplained_Vision | Garenbrig_Carver | Fling |
| 199 | Tournament_Grounds | Malevolent_Noble | Once_and_Future | Specter's_Shriek | Maraleaf_Pixie | Run_Away_Together | Giant's_Skewer | Garenbrig_Paladin | Cauldron_Familiar | Silverflame_Squire | Covetous_Urge | Irencrag_Feat | Rimrock_Knight | Rally_for_the_Throne | Ogre_Errant |
| 200 | Lost_Legion | Garenbrig_Paladin | Witch's_Cottage | Brimstone_Trebuchet | Garenbrig_Carver | Mystical_Dispute | Shepherd_of_the_Flock | Flaxen_Intruder | Overwhelmed_Apprentice | Shining_Armor | Moonlit_Scavengers | Faerie_Vandal | Arcanist's_Owl | Mysterious_Pathlighter | Tuinvale_Treefolk |
| 201 | Wicked_Guardian | Rosethorn_Acolyte | Ferocity_of_the_Wilds | Shinechaser | Vantress_Paladin | Silverflame_Squire | Reaper_of_Night | Shinechaser | Witch's_Cottage | Kenrith's_Transformation | Foreboding_Fruit | Ferocity_of_the_Wilds | Skullknocker_Ogre | All_That_Glitters | Irencrag_Feat |
| 202 | Malevolent_Noble | Lash_of_Thorns | Garenbrig_Paladin | Idyllic_Grange | Irencrag_Feat | Wandermare | Garenbrig_Paladin | Cauldron's_Gift | Faerie_Guidemother | Charmed_Sleep | Lost_Legion | Rosethorn_Acolyte | So_Tiny | Brimstone_Trebuchet | Rampart_Smasher |
| 203 | Rimrock_Knight | Reaper_of_Night | Rosethorn_Acolyte | Bloodhaze_Wolverine | Run_Away_Together | Shinechaser | Cauldron's_Gift | Witch's_Cottage | Specter's_Shriek | Curious_Pair | Burning-Yard_Trainer | Charmed_Sleep | Run_Away_Together | Deafening_Silence | Seven_Dwarves |
| 204 | Righteousness | Trail_of_Crumbs | Curious_Pair | Outflank | Witching_Well | Dance_of_the_Manse | Happily_Ever_After | Once_and_Future | All_That_Glitters | Shinechaser | Didn't_Say_Please | Witching_Well | Mystic_Sanctuary | Thrill_of_Possibility | Flaxen_Intruder |
| 205 | Witch's_Cottage | Syr_Faren_the_Hengehammer | Irencrag_Feat | Wintermoor_Commander | Fires_of_Invention | Raging_Redcap | Curious_Pair | Knight_of_the_Keep | Witching_Well | Prized_Griffin | Vantress_Paladin | Improbable_Alliance | Redcap_Melee | Rimrock_Knight | Garenbrig_Carver |
| 206 | Memory_Theft | Eye_Collector | Reaper_of_Night | Moonlit_Scavengers | Claim_the_Firstborn | Mystic_Sanctuary | All_That_Glitters | Mantle_of_Tides | Resolute_Rider | Overwhelmed_Apprentice | Mystical_Dispute | Claim_the_Firstborn | Claim_the_Firstborn | Silverflame_Squire | Venerable_Knight |
| 207 | Rally_for_the_Throne | Mystical_Dispute | Lost_Legion | Irencrag_Feat | Overwhelmed_Apprentice | Faerie_Guidemother | Tuinvale_Treefolk | Shining_Armor | Flutterfox | Tuinvale_Treefolk | Locthwain_Paladin | Overwhelmed_Apprentice | Lonesome_Unicorn | Ferocity_of_the_Wilds | Deathless_Knight |
| 208 | Happily_Ever_After | Animating_Faerie | Return_to_Nature | Happily_Ever_After | Garenbrig_Squire | Rally_for_the_Throne | Faerie_Guidemother | Garenbrig_Carver | Foreboding_Fruit | Witching_Well | Opt | Didn't_Say_Please | Youthful_Knight | Flutterfox | Happily_Ever_After |
| 209 | Lonesome_Unicorn | Frogify | Claim_the_Firstborn | Steelclaw_Lance | Barge_In | Ogre_Errant | Tempting_Witch | Steelgaze_Griffin | Lonesome_Unicorn | Rosethorn_Acolyte | Forever_Young | Redcap_Raiders | Outflank | Outflank | Redcap_Raiders |
| 210 | Inspiring_Veteran | Specter's_Shriek | Cauldron's_Gift | Eye_Collector | Fling | Merchant_of_the_Vale | Festive_Funeral | Mystic_Sanctuary | Into_the_Story | Silverflame_Ritual | Cauldron's_Gift | Fling | Deafening_Silence | Burning-Yard_Trainer | Dwarven_Mine |
| 211 | Locthwain_Paladin | Charmed_Sleep | Lash_of_Thorns | Loch_Dragon | Festive_Funeral | Flutterfox | Prized_Griffin | Silverflame_Squire | Righteousness | Flutterfox | Claim_the_Firstborn | Mystical_Dispute | Silverflame_Squire | Curious_Pair | Lash_of_Thorns |
| 212 | Thrill_of_Possibility | Outmuscle | Skullknocker_Ogre | Thrill_of_Possibility | Sage_of_the_Falls | Vantress_Paladin | Deafening_Silence | Wandermare | Silverflame_Ritual | Flaxen_Intruder | Raging_Redcap | Crystal_Slipper | Opt | Prized_Griffin | Locthwain_Paladin |
| 213 | Specter's_Shriek | Vantress_Paladin | Crystal_Slipper | Opt | Thrill_of_Possibility | Happily_Ever_After | Lonesome_Unicorn | Maraleaf_Pixie | Silverflame_Squire | True_Love's_Kiss | Unexplained_Vision | Opt | Merchant_of_the_Vale | Seven_Dwarves | Barge_In |
| 214 | Ferocity_of_the_Wilds | Gingerbread_Cabin | Sporecap_Spider | Fires_of_Invention | Redcap_Raiders | Steelgaze_Griffin | Wicked_Guardian | Tuinvale_Treefolk | Festive_Funeral | Idyllic_Grange | Skullknocker_Ogre | Thrill_of_Possibility | Righteousness | Raging_Redcap | Gingerbread_Cabin |
| 215 | Claim_the_Firstborn | Overwhelmed_Apprentice | Wicked_Guardian | Prized_Griffin | Blow_Your_House_Down | Shining_Armor | Specter's_Shriek | Lash_of_Thorns | Wishful_Merfolk | Deafening_Silence | Malevolent_Noble | Seven_Dwarves | Thrill_of_Possibility | Idyllic_Grange | Maraleaf_Rider |
| 216 | Skullknocker_Ogre | So_Tiny | Memory_Theft | Raging_Redcap | Memory_Theft | Claim_the_Firstborn | Lost_Legion | Idyllic_Grange | Cauldron's_Gift | Garenbrig_Carver | Weaselback_Redcap | Tome_Raider | Wishful_Merfolk | Ardenvale_Paladin | Weaselback_Redcap |
| 217 | Deafening_Silence | Run_Away_Together | Tall_as_a_Beanstalk | All_That_Glitters | Lash_of_Thorns | Unexplained_Vision | Return_to_Nature | Moonlit_Scavengers | Unexplained_Vision | Run_Away_Together | Irencrag_Feat | Dwarven_Mine | Corridor_Monitor | Skullknocker_Ogre | Lonesome_Unicorn |
| 218 | Festive_Funeral | Merfolk_Secretkeeper | Malevolent_Noble | Rally_for_the_Throne | Eye_Collector | Righteousness | Garenbrig_Carver | Maraleaf_Rider | Opt | Tome_Raider | Overwhelmed_Apprentice | Curious_Pair | Prized_Griffin | Fell_the_Pheasant | Barrow_Witches |
| 219 | Beloved_Princess | Curious_Pair | Foreboding_Fruit | Redcap_Raiders | Grumgully_the_Generous | Deafening_Silence | Ardenvale_Paladin | Rally_for_the_Throne | Eye_Collector | Vantress_Paladin | Lash_of_Thorns | Fell_the_Pheasant | Vantress_Paladin | Tall_as_a_Beanstalk | Deafening_Silence |
| 220 | Ogre_Errant | Garenbrig_Squire | Rosethorn_Halberd | Ardenvale_Paladin | Specter's_Shriek | Lonesome_Unicorn | Sporecap_Spider | Rosethorn_Halberd | Deafening_Silence | Opt | Witching_Well | Mystic_Sanctuary | Raging_Redcap | Maraleaf_Rider | Idyllic_Grange |
| 221 | Barrow_Witches | Rosethorn_Halberd | Embereth_Paladin | Didn't_Say_Please | Mystical_Dispute | Corridor_Monitor | Bartered_Cow | Memory_Theft | Vantress_Paladin | Didn't_Say_Please | Mistford_River_Turtle | Insatiable_Appetite | Flutterfox | Fortifying_Provisions | Return_to_Nature |
| 222 | Brimstone_Trebuchet | Memory_Theft | Festive_Funeral | Mystic_Sanctuary | So_Tiny | Ardenvale_Paladin | Witch's_Cottage | Ardenvale_Paladin | Wicked_Guardian | Merfolk_Secretkeeper | Witch's_Cottage | Tuinvale_Treefolk | Rally_for_the_Throne | Sporecap_Spider | Embereth_Paladin |
| 223 | Outflank | Tuinvale_Treefolk | Specter's_Shriek | Silverflame_Ritual | Opt | Prized_Griffin | Outflank | Eye_Collector | Lost_Legion | Queen_of_Ice | Wicked_Guardian | Maraleaf_Rider | Loch_Dragon | Crystal_Slipper | Rosethorn_Halberd |
| 224 | Idyllic_Grange | Fell_the_Pheasant | Garenbrig_Carver | Vantress_Paladin | Bloodhaze_Wolverine | Embereth_Paladin | Flutterfox | Merfolk_Secretkeeper | Outflank | Corridor_Monitor | Bloodhaze_Wolverine | Run_Away_Together | True_Love's_Kiss | Lonesome_Unicorn | Silverflame_Squire |
| 225 | True_Love's_Kiss | Didn't_Say_Please | Tempting_Witch | Corridor_Monitor | Rosethorn_Halberd | Weaselback_Redcap | Malevolent_Noble | Unexplained_Vision | Locthwain_Paladin | So_Tiny | Corridor_Monitor | So_Tiny | Blow_Your_House_Down | Ogre_Errant | Resolute_Rider |
| 226 | Silverflame_Squire | Opt | Barge_In | Wishful_Merfolk | Dwarven_Mine | Outflank | Shining_Armor | True_Love's_Kiss | Beloved_Princess | Maraleaf_Rider | Dwarven_Mine | Barge_In | Shining_Armor | Claim_the_Firstborn | Righteousness |
| 227 | Fling | Return_to_Nature | Thrill_of_Possibility | Claim_the_Firstborn | Fell_the_Pheasant | Skullknocker_Ogre | Maraleaf_Rider | Happily_Ever_After | Mystic_Sanctuary | Steelgaze_Griffin | Specter's_Shriek | Rosethorn_Halberd | Burning-Yard_Trainer | Beloved_Princess | Tournament_Grounds |
| 228 | Lash_of_Thorns | Mystic_Sanctuary | Fling | Ogre_Errant | Mystic_Sanctuary | Bartered_Cow | Wolf's_Quarry | Prized_Griffin | So_Tiny | Mystic_Sanctuary | Seven_Dwarves | Return_to_Nature | Mistford_River_Turtle | True_Love's_Kiss | Outflank |
| 229 | Youthful_Knight | Tome_Raider | Raging_Redcap | True_Love's_Kiss | Seven_Dwarves | Redcap_Raiders | Youthful_Knight | Corridor_Monitor | True_Love's_Kiss | Fell_the_Pheasant | Wishful_Merfolk | Garenbrig_Carver | Fling | Rosethorn_Halberd | True_Love's_Kiss |
| 230 | Raging_Redcap | Witching_Well | Maraleaf_Rider | Inspiring_Veteran | Sporecap_Spider | Ferocity_of_the_Wilds | Eye_Collector | Sporecap_Spider | Malevolent_Noble | Beloved_Princess | Memory_Theft | Mistford_River_Turtle | Seven_Dwarves | Blow_Your_House_Down | Shining_Armor |
| 231 | Flutterfox | Mistford_River_Turtle | Fell_the_Pheasant | Knight_of_the_Keep | Gingerbread_Cabin | True_Love's_Kiss | Beloved_Princess | Bartered_Cow | Moonlit_Scavengers | Fortifying_Provisions | Blow_Your_House_Down | Blow_Your_House_Down | Idyllic_Grange | Garenbrig_Squire | Blow_Your_House_Down |
| 232 | Eye_Collector | Maraleaf_Rider | Weaselback_Redcap | Steelgaze_Griffin | Moonlit_Scavengers | Silverflame_Ritual | Memory_Theft | Gingerbread_Cabin | Mistford_River_Turtle | Bartered_Cow | Festive_Funeral | Vantress_Paladin | Ferocity_of_the_Wilds | Silverflame_Ritual | Oakhame_Ranger |
| 233 | Blow_Your_House_Down | Garenbrig_Carver | Wildwood_Tracker | Deafening_Silence | Drown_in_the_Loch | Seven_Dwarves | Locthwain_Paladin | Vantress_Paladin | Prized_Griffin | Into_the_Story | Mystic_Sanctuary | Steelgaze_Griffin | Steelgaze_Griffin | Bloodhaze_Wolverine | Fell_the_Pheasant |
| 234 | Bartered_Cow | Unexplained_Vision | Seven_Dwarves | Mistford_River_Turtle | Corridor_Monitor | Fortifying_Provisions | Gingerbread_Cabin | Insatiable_Appetite | Idyllic_Grange | Unexplained_Vision | Mantle_of_Tides | Wishful_Merfolk | Ardenvale_Paladin | Wolf's_Quarry | Prized_Griffin |
| 235 | Embereth_Paladin | Corridor_Monitor | Wolf's_Quarry | Crystal_Slipper | Ferocity_of_the_Wilds | Mantle_of_Tides | Silverflame_Squire | Fell_the_Pheasant | Ardenvale_Paladin | Wolf's_Quarry | Fling | Corridor_Monitor | Bartered_Cow | Weaselback_Redcap | Fortifying_Provisions |
| 236 | Knight_of_the_Keep | Once_and_Future | Gingerbread_Cabin | Barge_In | Didn't_Say_Please | Blow_Your_House_Down | True_Love's_Kiss | Return_to_Nature | Lash_of_Thorns | Rosethorn_Halberd | Embereth_Paladin | Bloodhaze_Wolverine | Crystal_Slipper | Knight_of_the_Keep | Ardenvale_Paladin |
| 237 | Barge_In | Moonlit_Scavengers | Garenbrig_Squire | Fortifying_Provisions | Return_to_Nature | Wishful_Merfolk | Fortifying_Provisions | Wildwood_Tracker | Barrow_Witches | Tall_as_a_Beanstalk | Eye_Collector | Moonlit_Scavengers | Ogre_Errant | Embereth_Paladin | Tall_as_a_Beanstalk |
| 238 | Crystal_Slipper | Wicked_Guardian | Insatiable_Appetite | Embereth_Paladin | Insatiable_Appetite | Bloodhaze_Wolverine | Silverflame_Ritual | Deafening_Silence | Bartered_Cow | Moonlit_Scavengers | Steelgaze_Griffin | Wildwood_Tracker | Weaselback_Redcap | Insatiable_Appetite | Beloved_Princess |
| 239 | Bloodhaze_Wolverine | Steelgaze_Griffin | Locthwain_Paladin | Weaselback_Redcap | Wishful_Merfolk | Knight_of_the_Keep | Lash_of_Thorns | Wishful_Merfolk | Steelgaze_Griffin | Insatiable_Appetite | Ferocity_of_the_Wilds | Garenbrig_Squire | Knight_of_the_Keep | Wildwood_Tracker | Garenbrig_Squire |
| 240 | Ardenvale_Paladin | Wolf's_Quarry | Ogre_Errant | Blow_Your_House_Down | Skullknocker_Ogre | Beloved_Princess | Fell_the_Pheasant | Fortifying_Provisions | Memory_Theft | Mantle_of_Tides | Ogre_Errant | Tall_as_a_Beanstalk | Redcap_Raiders | Shining_Armor | Knight_of_the_Keep |
| 241 | Seven_Dwarves | Insatiable_Appetite | Eye_Collector | Beloved_Princess | Mistford_River_Turtle | Dwarven_Mine | Rosethorn_Halberd | Mistford_River_Turtle | Corridor_Monitor | Wildwood_Tracker | Crystal_Slipper | Unexplained_Vision | Embereth_Paladin | Fling | Silverflame_Ritual |
| 242 | Prized_Griffin | Mantle_of_Tides | Barrow_Witches | Seven_Dwarves | Wolf's_Quarry | Fling | Garenbrig_Squire | Wolf's_Quarry | Shining_Armor | Return_to_Nature | Barrow_Witches | Wolf's_Quarry | Fortifying_Provisions | Bartered_Cow | Youthful_Knight |
| 243 | Redcap_Raiders | Wildwood_Tracker | Blow_Your_House_Down | Bartered_Cow | Wildwood_Tracker | Mistford_River_Turtle | Idyllic_Grange | Beloved_Princess | Didn't_Say_Please | Gingerbread_Cabin | So_Tiny | Gingerbread_Cabin | Beloved_Princess | Youthful_Knight | Linden_the_Steadfast_Queen |
| 244 | Shining_Armor | Tall_as_a_Beanstalk | Redcap_Raiders | Shining_Armor | Unexplained_Vision | Idyllic_Grange | Insatiable_Appetite | Tall_as_a_Beanstalk | Youthful_Knight | Sporecap_Spider | Thrill_of_Possibility | Mantle_of_Tides | Bloodhaze_Wolverine | Barge_In | Insatiable_Appetite |
| 245 | Dwarven_Mine | Wishful_Merfolk | Robber_of_the_Rich | Skullknocker_Ogre | Tall_as_a_Beanstalk | Barge_In | Tall_as_a_Beanstalk | Garenbrig_Squire | Knight_of_the_Keep | Mistford_River_Turtle | Redcap_Raiders | Sporecap_Spider | Silverflame_Ritual | Dwarven_Mine | Wolf's_Quarry |
| 246 | Fortifying_Provisions | Sporecap_Spider | Bloodhaze_Wolverine | Fling | Mantle_of_Tides | Crystal_Slipper | Wildwood_Tracker | Oakhame_Ranger | Fortifying_Provisions | Wishful_Merfolk | Barge_In | Thunderous_Snapper | Mantle_of_Tides | Redcap_Raiders | Bartered_Cow |
| 247 | Weaselback_Redcap | Covetous_Urge | Dwarven_Mine | Mantle_of_Tides | Steelgaze_Griffin | Arcanist's_Owl | Barrow_Witches | Arcanist's_Owl | Mantle_of_Tides | Garenbrig_Squire | Loch_Dragon | Loch_Dragon | Dwarven_Mine | Fireborn_Knight | Wildwood_Tracker |
| 248 | Silverflame_Ritual | Thunderous_Snapper | Elite_Headhunter | Dwarven_Mine | Thunderous_Snapper | Loch_Dragon | Knight_of_the_Keep | Covetous_Urge | Rally_for_the_Throne | Arcanist's_Owl | Elite_Headhunter | Rampart_Smasher | Barge_In | Rampart_Smasher | Rally_for_the_Throne |
Second Prior: Bias to an Archetype Given a Draft Pool
What’s the math that governs how a person navigates a Draft? The value of cards in your current draft pool has a large impact on what the correct pick is in future packs. For example, even though Scorching Dragonfire is a better card than Outmuscle, if there are five green cards in a draft pool and zero red cards, Outmuscle is the correct pick.

Because of this, I believe that the bias towards an archetype is a function of archetypal card quality related to the draft pool. This means that draft decisions are not made by the general card quality in the pool by color, but rather by considering the total value a draft pool would provide to any specific archetype.

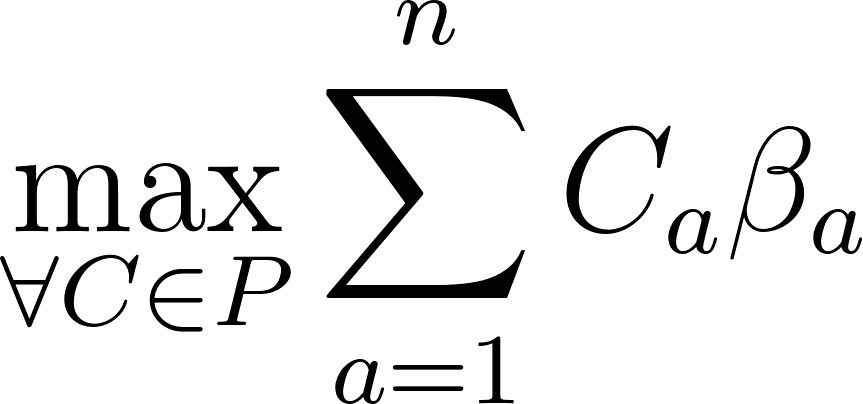
Overcoming Bad Human Behavior
The introduction of this bias tells the bot to stick to its archetype in a formal and structured way. At Pack 3 Pick 1, the bias towards the proper archetype will be large enough that it should fight improper drafting where a player takes an enticing card, often a rare, that they can’t really cast.
Notice that this fact isn’t hard-coded into the bot, but rather an emergent phenomenon that it learns as a consequence of the math. Furthermore, it appears that the bot behaves better than humans in this case! In the test set, approximately only 80% of picks by humans are in the proper archetype for Pack 3 Pick 1. However, the bot takes cards in the proper archetype 91% of the time at Pack 3 Pick 1 in the same test set, which is a substantial improvement.
Believe it or not, people actually raredraft on draft simulators!
Deriving the Defining Cards for Each Archetype
Furthermore, this math incentivizes the model to learn deviations in the value of cards that correspond to their archetypes. This means that the model can learn inflated values for gold cards within their archetypes, but assign them generic values low enough such that they aren’t picked until the bias to that color combination is high enough.
For example, Wandermare might be great and have a high power level in a WG adventure deck, but just like a human drafter would, the bot hedges and doesn't speculate on the Wandermare until the bias is sufficiently high.
This is a type of nuance that a generic pick order can never represent, but can easily be aggregated into a pick order for early picks! Below are the generic, unbiased, value of cards for the entire set — also known as the pick order for my bot at Pack 1 Pick 1, which achieved 70% accuracy (matching human picks) on the test set.
| learned_order | |
|---|---|
| 0 | Garruk_Cursed_Huntsman |
| 1 | Oko_Thief_of_Crowns |
| 2 | The_Great_Henge |
| 3 | Harmonious_Archon |
| 4 | Stonecoil_Serpent |
| 5 | Rankle_Master_of_Pranks |
| 6 | Clackbridge_Troll |
| 7 | Murderous_Rider |
| 8 | Realm-Cloaked_Giant |
| 9 | Questing_Beast |
| 10 | The_Circle_of_Loyalty |
| 11 | Wicked_Wolf |
| 12 | Embercleave |
| 13 | Feasting_Troll_King |
| 14 | Brazen_Borrower |
| 15 | Opportunistic_Dragon |
| 16 | Bonecrusher_Giant |
| 17 | Lochmere_Serpent |
| 18 | Gilded_Goose |
| 19 | Irencrag_Pyromancer |
| 20 | Lovestruck_Beast |
| 21 | Giant_Killer |
| 22 | Wildborn_Preserver |
| 23 | The_Royal_Scions |
| 24 | Torbran_Thane_of_Red_Fell |
| 25 | Stolen_by_the_Fae |
| 26 | Piper_of_the_Swarm |
| 27 | Gadwick_the_Wizened |
| 28 | Outlaws'_Merriment |
| 29 | Robber_of_the_Rich |
| 30 | Worthy_Knight |
| 31 | Yorvo_Lord_of_Garenbrig |
| 32 | Blacklance_Paragon |
| 33 | Oathsworn_Knight |
| 34 | Folio_of_Fancies |
| 35 | Syr_Konrad_the_Grim |
| 36 | Epic_Downfall |
| 37 | Sundering_Stroke |
| 38 | Bake_into_a_Pie |
| 39 | Acclaimed_Contender |
| 40 | Return_of_the_Wildspeaker |
| 41 | Revenge_of_Ravens |
| 42 | Order_of_Midnight |
| 43 | Witch's_Vengeance |
| 44 | Ayara_First_of_Locthwain |
| 45 | Vantress_Gargoyle |
| 46 | Syr_Carah_the_Bold |
| 47 | Lucky_Clover |
| 48 | Slaying_Fire |
| 49 | Syr_Alin_the_Lion's_Claw |
| 50 | Keeper_of_Fables |
| 51 | Midnight_Clock |
| 52 | Syr_Elenora_the_Discerning |
| 53 | Fae_of_Wishes |
| 54 | Edgewall_Innkeeper |
| 55 | Bog_Naughty |
| 56 | Arcanist's_Owl |
| 57 | Fabled_Passage |
| 58 | Archon_of_Absolution |
| 59 | Faerie_Vandal |
| 60 | The_Cauldron_of_Eternity |
| 61 | Beanstalk_Giant |
| 62 | Foulmire_Knight |
| 63 | Emry_Lurker_of_the_Loch |
| 64 | Once_Upon_a_Time |
| 65 | Reave_Soul |
| 66 | Savvy_Hunter |
| 67 | Hypnotic_Sprite |
| 68 | Linden_the_Steadfast_Queen |
| 69 | Scorching_Dragonfire |
| 70 | Glass_Casket |
| 71 | Rampart_Smasher |
| 72 | Deathless_Knight |
| 73 | Loch_Dragon |
| 74 | Fierce_Witchstalker |
| 75 | Animating_Faerie |
| 76 | Charming_Prince |
| 77 | Improbable_Alliance |
| 78 | Syr_Faren_the_Hengehammer |
| 79 | Fervent_Champion |
| 80 | Belle_of_the_Brawl |
| 81 | Resolute_Rider |
| 82 | Outmuscle |
| 83 | Fireborn_Knight |
| 84 | Turn_into_a_Pumpkin |
| 85 | Faeburrow_Elder |
| 86 | Oakhame_Ranger |
| 87 | Witch's_Oven |
| 88 | Mad_Ratter |
| 89 | Castle_Ardenvale |
| 90 | Trail_of_Crumbs |
| 91 | Grumgully_the_Generous |
| 92 | Oakhame_Adversary |
| 93 | Ardenvale_Tactician |
| 94 | Castle_Locthwain |
| 95 | Clockwork_Servant |
| 96 | Mysterious_Pathlighter |
| 97 | Castle_Vantress |
| 98 | Heraldic_Banner |
| 99 | Inspiring_Veteran |
| 100 | Enchanted_Carriage |
| 101 | Charmed_Sleep |
| 102 | Trapped_in_the_Tower |
| 103 | Stormfist_Crusader |
| 104 | Elite_Headhunter |
| 105 | Covetous_Urge |
| 106 | Searing_Barrage |
| 107 | Thunderous_Snapper |
| 108 | Maraleaf_Pixie |
| 109 | Merfolk_Secretkeeper |
| 110 | Joust |
| 111 | Cauldron_Familiar |
| 112 | Spinning_Wheel |
| 113 | Mirrormade |
| 114 | Burning-Yard_Trainer |
| 115 | Steelclaw_Lance |
| 116 | Sage_of_the_Falls |
| 117 | Hushbringer |
| 118 | The_Magic_Mirror |
| 119 | Tome_Raider |
| 120 | Redcap_Melee |
| 121 | Wintermoor_Commander |
| 122 | Drown_in_the_Loch |
| 123 | Shepherd_of_the_Flock |
| 124 | Wandermare |
| 125 | Castle_Embereth |
| 126 | Golden_Egg |
| 127 | Scalding_Cauldron |
| 128 | Castle_Garenbrig |
| 129 | Rosethorn_Acolyte |
| 130 | Overwhelmed_Apprentice |
| 131 | Giant_Opportunity |
| 132 | Into_the_Story |
| 133 | Garenbrig_Paladin |
| 134 | Frogify |
| 135 | Embereth_Shieldbreaker |
| 136 | Smitten_Swordmaster |
| 137 | Kenrith's_Transformation |
| 138 | Queen_of_Ice |
| 139 | Run_Away_Together |
| 140 | Once_and_Future |
| 141 | Escape_to_the_Wilds |
| 142 | Venerable_Knight |
| 143 | Didn't_Say_Please |
| 144 | Lost_Legion |
| 145 | Dance_of_the_Manse |
| 146 | Tempting_Witch |
| 147 | Merchant_of_the_Vale |
| 148 | Doom_Foretold |
| 149 | Foreboding_Fruit |
| 150 | Youthful_Knight |
| 151 | Rimrock_Knight |
| 152 | Curious_Pair |
| 153 | So_Tiny |
| 154 | Witching_Well |
| 155 | Brimstone_Trebuchet |
| 156 | Wishclaw_Talisman |
| 157 | Shinechaser |
| 158 | Opt |
| 159 | Raging_Redcap |
| 160 | Faerie_Guidemother |
| 161 | Flutterfox |
| 162 | Fires_of_Invention |
| 163 | Tuinvale_Treefolk |
| 164 | Reaper_of_Night |
| 165 | Sorcerer's_Broom |
| 166 | Forever_Young |
| 167 | Garenbrig_Carver |
| 168 | Rally_for_the_Throne |
| 169 | Locthwain_Paladin |
| 170 | Seven_Dwarves |
| 171 | Silverflame_Squire |
| 172 | Gingerbrute |
| 173 | Shambling_Suit |
| 174 | Cauldron's_Gift |
| 175 | Ogre_Errant |
| 176 | Unexplained_Vision |
| 177 | Lonesome_Unicorn |
| 178 | Flaxen_Intruder |
| 179 | Tournament_Grounds |
| 180 | All_That_Glitters |
| 181 | Thrill_of_Possibility |
| 182 | Mystical_Dispute |
| 183 | Moonlit_Scavengers |
| 184 | Malevolent_Noble |
| 185 | Maraleaf_Rider |
| 186 | Ferocity_of_the_Wilds |
| 187 | Vantress_Paladin |
| 188 | Steelgaze_Griffin |
| 189 | Sporecap_Spider |
| 190 | Wicked_Guardian |
| 191 | Giant's_Skewer |
| 192 | Prized_Griffin |
| 193 | Barrow_Witches |
| 194 | Festive_Funeral |
| 195 | Redcap_Raiders |
| 196 | Outflank |
| 197 | Bloodhaze_Wolverine |
| 198 | Weaselback_Redcap |
| 199 | Skullknocker_Ogre |
| 200 | Sorcerous_Spyglass |
| 201 | Garenbrig_Squire |
| 202 | Embereth_Paladin |
| 203 | Mystic_Sanctuary |
| 204 | Wildwood_Tracker |
| 205 | Crashing_Drawbridge |
| 206 | Eye_Collector |
| 207 | Henge_Walker |
| 208 | Gingerbread_Cabin |
| 209 | Rosethorn_Halberd |
| 210 | Silverflame_Ritual |
| 211 | Claim_the_Firstborn |
| 212 | Irencrag_Feat |
| 213 | Witch's_Cottage |
| 214 | Corridor_Monitor |
| 215 | Inquisitive_Puppet |
| 216 | Insatiable_Appetite |
| 217 | Righteousness |
| 218 | Jousting_Dummy |
| 219 | Prophet_of_the_Peak |
| 220 | Barge_In |
| 221 | Ardenvale_Paladin |
| 222 | Memory_Theft |
| 223 | Mantle_of_Tides |
| 224 | Lash_of_Thorns |
| 225 | Mistford_River_Turtle |
| 226 | Return_to_Nature |
| 227 | Fell_the_Pheasant |
| 228 | Fling |
| 229 | Specter's_Shriek |
| 230 | Crystal_Slipper |
| 231 | Shining_Armor |
| 232 | Wishful_Merfolk |
| 233 | Knight_of_the_Keep |
| 234 | Happily_Ever_After |
| 235 | Idyllic_Grange |
| 236 | Tall_as_a_Beanstalk |
| 237 | Dwarven_Mine |
| 238 | Wolf's_Quarry |
| 239 | Weapon_Rack |
| 240 | Locthwain_Gargoyle |
| 241 | Fortifying_Provisions |
| 242 | Signpost_Scarecrow |
| 243 | Blow_Your_House_Down |
| 244 | True_Love's_Kiss |
| 245 | Beloved_Princess |
| 246 | Roving_Keep |
| 247 | Bartered_Cow |
| 248 | Deafening_Silence |
This pick order is actually different than the one that would correspond to the sum of the archetypal pick orders described in the previous section. This is because I used the earlier matrix just to initialize my bots “understanding” of archetypes. And I allowed the model to update those values in order to satisfy the math I just described.
Additionally, given that the values I used to initialize the model have an embedded representation of archetype and color, the gradients that correspond to these weights — the math that governs how to update/learn the value of cards in this system — are unlikely to maneuver these values in a manner that fundamentally shifts the archetypal vector (e.g. the Izzet vector will not represent aspects of Golgari, however it is possible for smaller deviations where the Mono-Red archetype represents aspects of Izzet). So, according to this methodology, what does the model learn?
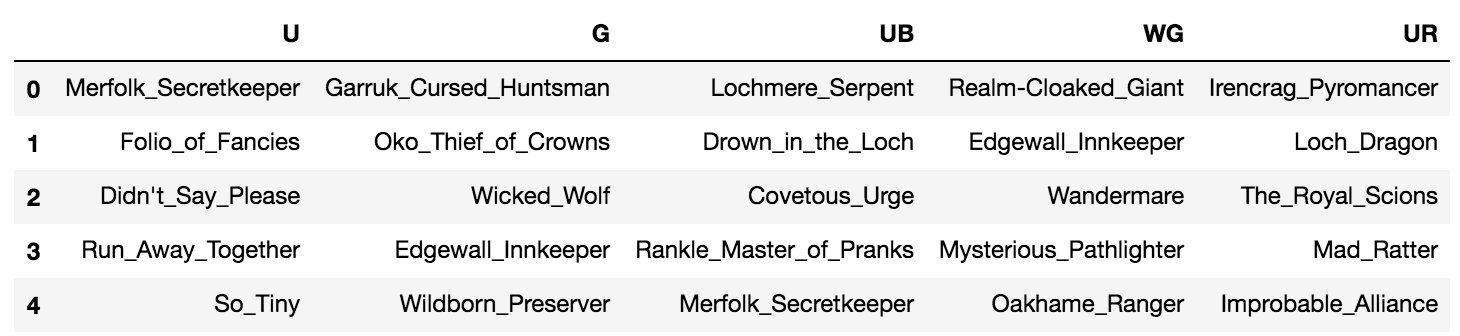
Merfolk Secretkeeper is in the top five cards in the set for Dimir and Mono-Blue according to this archetypal representation. But It’s not a top five card in the set for those archetypes because of rares and efficient uncommons. What these lists above effectively represent are the cards with the largest delta from that archetype to the other archetypes. This is because this feature is used to compute pull towards archetype.
Merfolk Secretkeeper doesn’t create much of a bias towards Simic, but it certainly gets me thinking about Mono-Blue and Dimir.

Intuitively, the model learned what I call archetypal inflation. Look at the Selesnya section of the above table. Selesnya has the best adventure rare first, followed by the three uncommon adventure payoffs, and lastly the worst of the hybrid uncommons.
First off, why are any of these represented more than Lucky Clover (which is a couple more slots down, but not far behind)? It’s because Lucky Clover is solid in enough other places that it doesn’t need as incredible of an inflation factor for Selesnya. Wandermare, Mysterious Pathlighter, and Oakhame Ranger all are quite good in Selesnya and mediocre to unplayable elsewhere.
By definition, this means they should create a specific pull towards Selesnya. And Edgewall Innkeeper is incredibly high here because, while it does pull towards green in general — as can be seen by being in the top five for mono-green as well — it creates the largest pull to white as a secondary color thanks to the density of adventure cards.
But these results don't just represent the obvious synergies like adventure for Selesnya or draw-two for Izzet. The best rares will jump to the top. For example Garruk, Cursed Huntsman, Embercleave, and Oko, Thief of Crowns surface because their value has to be so high.
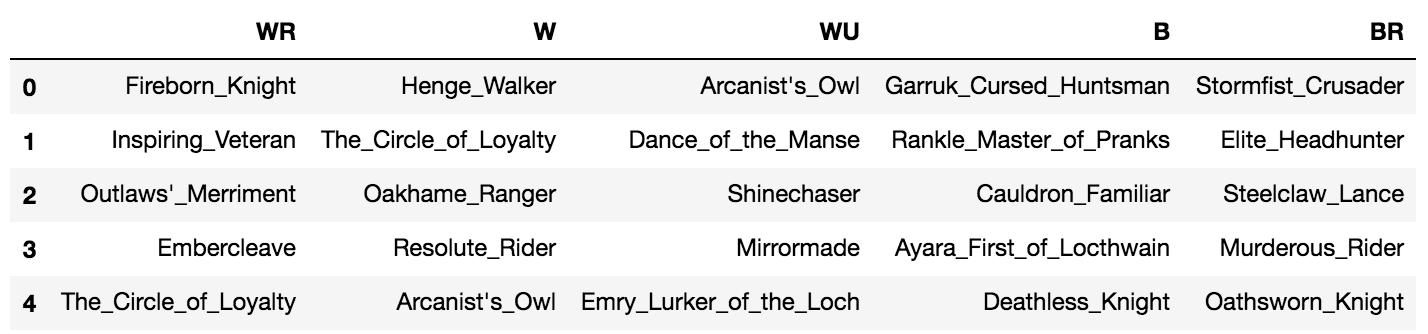
And, as I expected, it learned to largely inflate the value of gold cards in their respective archetypes like Shinechaser and Steelclaw Lance. It’s also why hybrid cards like Arcanist's Owl, Fireborn Knight, and Elite Headhunter are close to the top in all of their corresponding latent vectors.
And it’s also why Henge Walker is all the way at the top for mono-white. Mono-white has artifact synergies with Arcanist’s Owl and Flutterfox, but it also has a huge gap in the three-drop slot. The only good common three-drop for white is Ardenvale Tactician, and that card is taken so highly that it’s impossible to guarantee even one copy. And neither Knight of the Keep nor Lonesome Unicorn are particularly good cards. Hence, Henge Walker is likely largely inflated in mono-white because it plays an important role there while also being a colorless card that needs reasonable representation.
Inspecting this aspect of my bot is what I’m most excited for in future formats. Henge Walker at the top of mono-white raises an eyebrow, but actually makes a lot of sense upon inspection. Furthermore, note that mono-white is the only mono-colored archetype to contain multiple hybrid cards. This isn’t random. The specific incentive for mono-white is a density of uncommon hybrid cards, where other mono-colored archetypes have other incentives. Delving into the latent archetypal representations of Theros Beyond Death may reveal similar subtleties.
However, not all of these representations are as good. Cauldron Familiar at the top of mono-black is concerning. I believe this is because the math I implemented says nothing explicit about synergy. The algorithm can learn an archetypal representation of synergy, but it can’t easily represent smaller synergy pockets like Cauldron Familiar and Witch's Oven.
Given that the Oven is not too far behind in this vector, I imagine that the algorithm learned to represent them both very highly in mono black, and let black bias increase their value. Unfortunately, this yields some odd cases of overfitting: where the algorithm learns exploitations of the dataset it’s trained on rather than the fundamentals in the game. I use techniques like regularization to try and fight overfitting, but I also intend to add synergy logic in the future to handle this case.
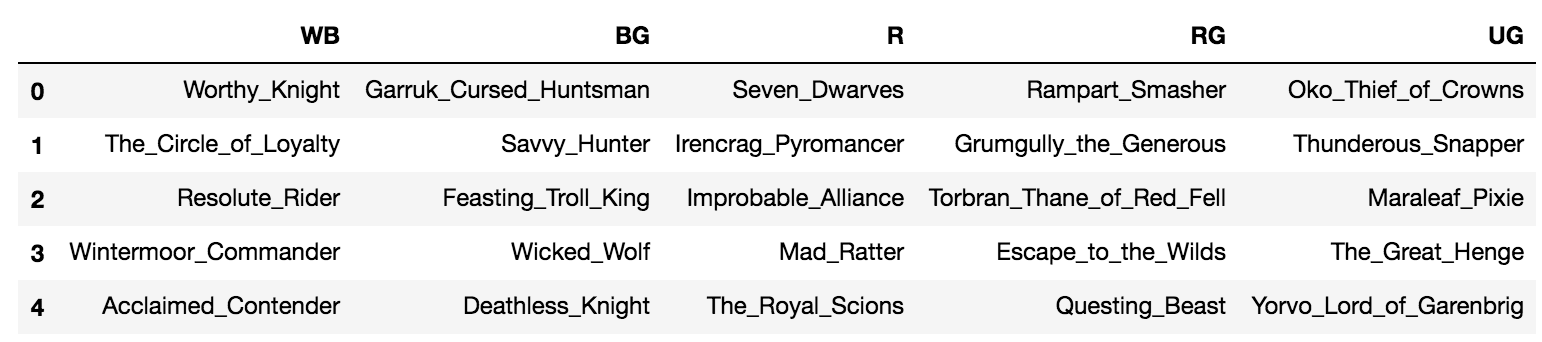
Just for completion, this is the last part of the top five learned archetypal weights. There is a clear problem with mono-red. It’s a lot more representative of Izzet than it likely should be. And I’m not entirely sure why this is the case.
My best guess is that in order to reprioritize the proper red card draw synergies (e.g. with multiple copies of Mad Ratter, Merchant of the Vale becomes an extremely high pick even if the deck is not Izzet), they all got additional representation in mono-red to enable that flexibility when navigating a draft. Importantly, this doesn’t mean that mono red is actually drafted like Izzet. Here is a draft log from the bot, where it drafted a pretty phenomenal mono-red deck that clearly demonstrates the ability to differentiate mono-red from base-red Izzet.
Below is the full learned matrix if you want to drill further down than just the top five picks per archetype. Notice that it isn't perfect, and there are clear erroneous cases sprinkled throughout such as Seven Dwarves being represented highly in Dimir. These cases happen due to the complexity of the problem, and I intend to explore how to prevent them. However, this still demonstrates a reasonable abstract representation of archetypes, and I don't believe undermines the interpretability of the algorithm.
| UG | WR | WU | G | W | B | UR | R | RG | BR | WG | WB | BG | UB | U | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Oko_Thief_of_Crowns | Fireborn_Knight | Arcanist's_Owl | Garruk_Cursed_Huntsman | Henge_Walker | Garruk_Cursed_Huntsman | Irencrag_Pyromancer | Seven_Dwarves | Rampart_Smasher | Stormfist_Crusader | Realm-Cloaked_Giant | Worthy_Knight | Garruk_Cursed_Huntsman | Lochmere_Serpent | Merfolk_Secretkeeper |
| 1 | Thunderous_Snapper | Inspiring_Veteran | Dance_of_the_Manse | Oko_Thief_of_Crowns | The_Circle_of_Loyalty | Rankle_Master_of_Pranks | Loch_Dragon | Irencrag_Pyromancer | Grumgully_the_Generous | Elite_Headhunter | Edgewall_Innkeeper | The_Circle_of_Loyalty | Savvy_Hunter | Drown_in_the_Loch | Folio_of_Fancies |
| 2 | Maraleaf_Pixie | Outlaws'_Merriment | Shinechaser | Wicked_Wolf | Oakhame_Ranger | Cauldron_Familiar | The_Royal_Scions | Improbable_Alliance | Torbran_Thane_of_Red_Fell | Steelclaw_Lance | Wandermare | Resolute_Rider | Feasting_Troll_King | Covetous_Urge | Didn't_Say_Please |
| 3 | The_Great_Henge | Embercleave | Mirrormade | Edgewall_Innkeeper | Resolute_Rider | Ayara_First_of_Locthwain | Mad_Ratter | Mad_Ratter | Escape_to_the_Wilds | Murderous_Rider | Mysterious_Pathlighter | Wintermoor_Commander | Wicked_Wolf | Rankle_Master_of_Pranks | Run_Away_Together |
| 4 | Yorvo_Lord_of_Garenbrig | The_Circle_of_Loyalty | Emry_Lurker_of_the_Loch | Wildborn_Preserver | Arcanist's_Owl | Deathless_Knight | Improbable_Alliance | The_Royal_Scions | Questing_Beast | Oathsworn_Knight | Oakhame_Ranger | Acclaimed_Contender | Deathless_Knight | Merfolk_Secretkeeper | So_Tiny |
| 5 | Questing_Beast | Worthy_Knight | All_That_Glitters | Rampart_Smasher | Realm-Cloaked_Giant | Murderous_Rider | Arcanist's_Owl | Thrill_of_Possibility | Yorvo_Lord_of_Garenbrig | Embercleave | Giant_Killer | Harmonious_Archon | Clackbridge_Troll | Murderous_Rider | Stolen_by_the_Fae |
| 6 | Gadwick_the_Wizened | Torbran_Thane_of_Red_Fell | Hushbringer | Lovestruck_Beast | Harmonious_Archon | Eye_Collector | Faerie_Vandal | Blow_Your_House_Down | Opportunistic_Dragon | Fervent_Champion | Harmonious_Archon | Oathsworn_Knight | Gilded_Goose | Vantress_Gargoyle | Redcap_Melee |
| 7 | Wicked_Wolf | Acclaimed_Contender | The_Magic_Mirror | Beanstalk_Giant | Fireborn_Knight | Clackbridge_Troll | Opportunistic_Dragon | Bloodhaze_Wolverine | Return_of_the_Wildspeaker | Blacklance_Paragon | Lucky_Clover | Blacklance_Paragon | Bog_Naughty | Seven_Dwarves | Charmed_Sleep |
| 8 | Stolen_by_the_Fae | Burning-Yard_Trainer | Shambling_Suit | The_Great_Henge | Worthy_Knight | Gingerbrute | Stolen_by_the_Fae | Inspiring_Veteran | The_Great_Henge | Torbran_Thane_of_Red_Fell | Faeburrow_Elder | Giant_Killer | Trail_of_Crumbs | Folio_of_Fancies | Overwhelmed_Apprentice |
| 9 | Feasting_Troll_King | Bonecrusher_Giant | Linden_the_Steadfast_Queen | Keeper_of_Fables | Jousting_Dummy | Syr_Konrad_the_Grim | Embercleave | Fling | Bonecrusher_Giant | Piper_of_the_Swarm | The_Great_Henge | Clackbridge_Troll | The_Great_Henge | Syr_Konrad_the_Grim | Turn_into_a_Pumpkin |
| 10 | Wildborn_Preserver | Arcanist's_Owl | Happily_Ever_After | Outmuscle | Linden_the_Steadfast_Queen | Bog_Naughty | Gadwick_the_Wizened | Merchant_of_the_Vale | Wildborn_Preserver | Rankle_Master_of_Pranks | Lovestruck_Beast | Murderous_Rider | Questing_Beast | Emry_Lurker_of_the_Loch | Vantress_Gargoyle |
| 11 | Brazen_Borrower | Opportunistic_Dragon | Harmonious_Archon | Feasting_Troll_King | Acclaimed_Contender | Witch's_Oven | Brazen_Borrower | Embercleave | Ferocity_of_the_Wilds | Irencrag_Pyromancer | Shepherd_of_the_Flock | Realm-Cloaked_Giant | Piper_of_the_Swarm | Overwhelmed_Apprentice | Into_the_Story |
| 12 | Lovestruck_Beast | Fervent_Champion | Castle_Vantress | Oakhame_Adversary | Syr_Alin_the_Lion's_Claw | Tempting_Witch | Bonecrusher_Giant | Claim_the_Firstborn | Embercleave | Wishclaw_Talisman | Faerie_Guidemother | Piper_of_the_Swarm | Giant_Opportunity | Revenge_of_Ravens | Gadwick_the_Wizened |
| 13 | Gilded_Goose | Joust | Charming_Prince | Fierce_Witchstalker | Crashing_Drawbridge | Savvy_Hunter | Torbran_Thane_of_Red_Fell | Barge_In | Feasting_Troll_King | Witch's_Vengeance | Ardenvale_Tactician | Archon_of_Absolution | Rankle_Master_of_Pranks | Piper_of_the_Swarm | Midnight_Clock |
| 14 | Return_of_the_Wildspeaker | Syr_Alin_the_Lion's_Claw | Wishclaw_Talisman | Questing_Beast | Scalding_Cauldron | Giant's_Skewer | Slaying_Fire | Crystal_Slipper | Robber_of_the_Rich | Ayara_First_of_Locthwain | Silverflame_Squire | Syr_Alin_the_Lion's_Claw | Tempting_Witch | Clackbridge_Troll | Irencrag_Pyromancer |
| 15 | Syr_Faren_the_Hengehammer | Syr_Carah_the_Bold | Sorcerous_Spyglass | Thunderous_Snapper | Ardenvale_Tactician | Elite_Headhunter | Syr_Elenora_the_Discerning | Tournament_Grounds | Wicked_Wolf | Sundering_Stroke | Outlaws'_Merriment | Rankle_Master_of_Pranks | Lovestruck_Beast | Ayara_First_of_Locthwain | Golden_Egg |
| 16 | Folio_of_Fancies | Redcap_Melee | Doom_Foretold | Gilded_Goose | Signpost_Scarecrow | Revenge_of_Ravens | Syr_Carah_the_Bold | Embereth_Paladin | Lovestruck_Beast | Robber_of_the_Rich | Archon_of_Absolution | Linden_the_Steadfast_Queen | Bake_into_a_Pie | Brazen_Borrower | Scalding_Cauldron |
| 17 | Once_Upon_a_Time | Slaying_Fire | Giant_Killer | Maraleaf_Pixie | Youthful_Knight | Bake_into_a_Pie | Scorching_Dragonfire | Weaselback_Redcap | Redcap_Raiders | Order_of_Midnight | Syr_Alin_the_Lion's_Claw | Epic_Downfall | Witch's_Oven | Stolen_by_the_Fae | Mystic_Sanctuary |
| 18 | Hypnotic_Sprite | Glass_Casket | Realm-Cloaked_Giant | Animating_Faerie | Lonesome_Unicorn | Lash_of_Thorns | Sundering_Stroke | Raging_Redcap | Keeper_of_Fables | Burning-Yard_Trainer | Lonesome_Unicorn | Order_of_Midnight | Murderous_Rider | Bake_into_a_Pie | Moonlit_Scavengers |
| 19 | Syr_Elenora_the_Discerning | Ardenvale_Tactician | Castle_Ardenvale | Trail_of_Crumbs | Clockwork_Servant | Oathsworn_Knight | Robber_of_the_Rich | Syr_Carah_the_Bold | Gilded_Goose | Bonecrusher_Giant | Charming_Prince | Belle_of_the_Brawl | Witch's_Vengeance | Fae_of_Wishes | Lucky_Clover |
| 20 | Keeper_of_Fables | Steelclaw_Lance | Deafening_Silence | Syr_Faren_the_Hengehammer | Idyllic_Grange | Foulmire_Knight | Tome_Raider | Rimrock_Knight | Castle_Embereth | Opportunistic_Dragon | Beanstalk_Giant | Syr_Konrad_the_Grim | The_Cauldron_of_Eternity | Midnight_Clock | Scorching_Dragonfire |
| 21 | Worthy_Knight | Giant_Killer | Gadwick_the_Wizened | Yorvo_Lord_of_Garenbrig | Silverflame_Ritual | Giant_Opportunity | Merchant_of_the_Vale | Scorching_Dragonfire | Skullknocker_Ogre | Belle_of_the_Brawl | The_Circle_of_Loyalty | Venerable_Knight | Cauldron_Familiar | Witch's_Vengeance | Hypnotic_Sprite |
| 22 | Vantress_Gargoyle | Rampart_Smasher | Brazen_Borrower | Deathless_Knight | Prized_Griffin | Wildwood_Tracker | Animating_Faerie | Slaying_Fire | Wildwood_Tracker | Smitten_Swordmaster | Wildborn_Preserver | Doom_Foretold | Lochmere_Serpent | Didn't_Say_Please | Witching_Well |
| 23 | Fae_of_Wishes | Trapped_in_the_Tower | Righteousness | Order_of_Midnight | Ardenvale_Paladin | Order_of_Midnight | Charmed_Sleep | Stormfist_Crusader | Seven_Dwarves | Garruk_Cursed_Huntsman | Yorvo_Lord_of_Garenbrig | Bake_into_a_Pie | Once_Upon_a_Time | Gadwick_the_Wizened | Syr_Elenora_the_Discerning |
| 24 | Oakhame_Adversary | Scorching_Dragonfire | Inquisitive_Puppet | Curious_Pair | Prophet_of_the_Peak | Piper_of_the_Swarm | Sage_of_the_Falls | Wolf's_Quarry | Castle_Garenbrig | Castle_Embereth | Gilded_Goose | Reave_Soul | Outlaws'_Merriment | Epic_Downfall | Mad_Ratter |
| 25 | Tome_Raider | Brimstone_Trebuchet | Fae_of_Wishes | Stonecoil_Serpent | Locthwain_Gargoyle | Resolute_Rider | Searing_Barrage | Embereth_Shieldbreaker | Once_Upon_a_Time | Fires_of_Invention | Garenbrig_Carver | Youthful_Knight | Wildborn_Preserver | The_Cauldron_of_Eternity | Slaying_Fire |
| 26 | Beanstalk_Giant | Rimrock_Knight | Vantress_Gargoyle | Garenbrig_Squire | Mysterious_Pathlighter | Merfolk_Secretkeeper | Turn_into_a_Pumpkin | Opportunistic_Dragon | Sundering_Stroke | Castle_Locthwain | Questing_Beast | Trapped_in_the_Tower | Fierce_Witchstalker | Reave_Soul | Searing_Barrage |
| 27 | Midnight_Clock | Robber_of_the_Rich | Faeburrow_Elder | Garenbrig_Carver | Brimstone_Trebuchet | Blacklance_Paragon | Bloodhaze_Wolverine | Ogre_Errant | Fires_of_Invention | Embereth_Shieldbreaker | Trapped_in_the_Tower | Witch's_Vengeance | Castle_Locthwain | Hypnotic_Sprite | Unexplained_Vision |
| 28 | Charmed_Sleep | Embereth_Shieldbreaker | Animating_Faerie | Rosethorn_Acolyte | Heraldic_Banner | Smitten_Swordmaster | Covetous_Urge | Lash_of_Thorns | Faeburrow_Elder | Doom_Foretold | Rosethorn_Acolyte | Glass_Casket | Sorcerer's_Broom | So_Tiny | Tome_Raider |
| 29 | Overwhelmed_Apprentice | Sundering_Stroke | Irencrag_Feat | Shinechaser | Trapped_in_the_Tower | Epic_Downfall | Redcap_Melee | Dwarven_Mine | Irencrag_Feat | Syr_Konrad_the_Grim | Wicked_Wolf | Revenge_of_Ravens | Yorvo_Lord_of_Garenbrig | Frogify | Drown_in_the_Loch |
| 30 | Faerie_Vandal | Realm-Cloaked_Giant | Midnight_Clock | Bog_Naughty | Wandermare | Foreboding_Fruit | Hypnotic_Sprite | Steelclaw_Lance | Syr_Faren_the_Hengehammer | Joust | Feasting_Troll_King | Rally_for_the_Throne | Epic_Downfall | Reaper_of_Night | Loch_Dragon |
| 31 | Queen_of_Ice | Harmonious_Archon | Sorcerer's_Broom | Epic_Downfall | Flutterfox | Locthwain_Paladin | Harmonious_Archon | Irencrag_Feat | Rosethorn_Halberd | Foulmire_Knight | Flaxen_Intruder | Lochmere_Serpent | Syr_Konrad_the_Grim | Queen_of_Ice | Sage_of_the_Falls |
| 32 | Fierce_Witchstalker | Archon_of_Absolution | Stolen_by_the_Fae | Sorcerer's_Broom | Knight_of_the_Keep | Lost_Legion | Elite_Headhunter | Brimstone_Trebuchet | Slaying_Fire | Clackbridge_Troll | Glass_Casket | Foulmire_Knight | Oko_Thief_of_Crowns | Foulmire_Knight | Opt |
| 33 | Turn_into_a_Pumpkin | Flutterfox | Folio_of_Fancies | Once_and_Future | Faerie_Guidemother | Forever_Young | Midnight_Clock | Fervent_Champion | The_Magic_Mirror | The_Cauldron_of_Eternity | Tuinvale_Treefolk | Castle_Ardenvale | Wishclaw_Talisman | Castle_Locthwain | Queen_of_Ice |
| 34 | Frogify | Venerable_Knight | Mystical_Dispute | Return_of_the_Wildspeaker | Glass_Casket | Overwhelmed_Apprentice | Rampart_Smasher | Mantle_of_Tides | Fervent_Champion | Syr_Carah_the_Bold | Castle_Ardenvale | Charming_Prince | Ayara_First_of_Locthwain | Blacklance_Paragon | Bonecrusher_Giant |
| 35 | Castle_Vantress | Raging_Redcap | Fires_of_Invention | Tuinvale_Treefolk | Giant_Killer | Malevolent_Noble | Emry_Lurker_of_the_Loch | Insatiable_Appetite | Oakhame_Adversary | Tournament_Grounds | Curious_Pair | Ayara_First_of_Locthwain | Outmuscle | Eye_Collector | Faerie_Vandal |
| 36 | Outmuscle | Oko_Thief_of_Crowns | Rally_for_the_Throne | Garenbrig_Paladin | Outflank | Rosethorn_Halberd | Thrill_of_Possibility | Castle_Embereth | Kenrith's_Transformation | Irencrag_Feat | Garenbrig_Squire | Smitten_Swordmaster | Reave_Soul | Into_the_Story | Arcanist's_Owl |
| 37 | Vantress_Paladin | Stormfist_Crusader | Frogify | Scalding_Cauldron | Archon_of_Absolution | Wicked_Wolf | Vantress_Gargoyle | Redcap_Raiders | Raging_Redcap | Fabled_Passage | Keeper_of_Fables | Ardenvale_Tactician | Beanstalk_Giant | Vantress_Paladin | Mystical_Dispute |
| 38 | Garenbrig_Paladin | Ogre_Errant | Beloved_Princess | Lucky_Clover | Silverflame_Squire | Curious_Pair | Steelgaze_Griffin | Ferocity_of_the_Wilds | Linden_the_Steadfast_Queen | Escape_to_the_Wilds | Linden_the_Steadfast_Queen | Drown_in_the_Loch | Revenge_of_Ravens | Charmed_Sleep | Animating_Faerie |
| 39 | Loch_Dragon | Elite_Headhunter | Fortifying_Provisions | Shambling_Suit | Venerable_Knight | Feasting_Troll_King | Realm-Cloaked_Giant | Fires_of_Invention | Barge_In | The_Royal_Scions | Hushbringer | Hushbringer | Return_of_the_Wildspeaker | Lucky_Clover | Signpost_Scarecrow |
| 40 | Castle_Garenbrig | Seven_Dwarves | Maraleaf_Pixie | Kenrith's_Transformation | Weapon_Rack | Belle_of_the_Brawl | Fae_of_Wishes | Loch_Dragon | Garenbrig_Paladin | Epic_Downfall | Oakhame_Adversary | Castle_Locthwain | Oakhame_Adversary | Stormfist_Crusader | Wishful_Merfolk |
| 41 | Run_Away_Together | Youthful_Knight | Corridor_Monitor | Reave_Soul | Gingerbrute | Covetous_Urge | Lochmere_Serpent | Fell_the_Pheasant | Claim_the_Firstborn | Slaying_Fire | Worthy_Knight | Outflank | Once_and_Future | Order_of_Midnight | Stonecoil_Serpent |
| 42 | The_Royal_Scions | Searing_Barrage | Castle_Garenbrig | Giant_Opportunity | Shining_Armor | Reave_Soul | Stonecoil_Serpent | Opt | Oakhame_Ranger | Happily_Ever_After | Fierce_Witchstalker | Shepherd_of_the_Flock | Castle_Garenbrig | Castle_Vantress | Corridor_Monitor |
| 43 | Merfolk_Secretkeeper | Charming_Prince | Outlaws'_Merriment | Piper_of_the_Swarm | Castle_Ardenvale | Memory_Theft | Clockwork_Servant | Wishful_Merfolk | Garruk_Cursed_Huntsman | Embereth_Paladin | Merfolk_Secretkeeper | Covetous_Urge | Keeper_of_Fables | Bog_Naughty | Syr_Carah_the_Bold |
| 44 | Into_the_Story | Tournament_Grounds | Acclaimed_Contender | Rankle_Master_of_Pranks | Locthwain_Paladin | Tall_as_a_Beanstalk | Opt | Beloved_Princess | Maraleaf_Rider | Skullknocker_Ogre | Once_Upon_a_Time | Barrow_Witches | Foreboding_Fruit | Run_Away_Together | Epic_Downfall |
| 45 | Sage_of_the_Falls | Shinechaser | The_Royal_Scions | Malevolent_Noble | Enchanted_Carriage | Cauldron's_Gift | Rankle_Master_of_Pranks | Searing_Barrage | Dwarven_Mine | Brimstone_Trebuchet | Prized_Griffin | Stonecoil_Serpent | Curious_Pair | Animating_Faerie | Mistford_River_Turtle |
| 46 | Inspiring_Veteran | Shambling_Suit | Fabled_Passage | Witch's_Oven | Charming_Prince | Trail_of_Crumbs | Queen_of_Ice | Wintermoor_Commander | Weaselback_Redcap | Claim_the_Firstborn | Flutterfox | The_Cauldron_of_Eternity | Inspiring_Veteran | Witching_Well | Merchant_of_the_Vale |
| 47 | Didn't_Say_Please | Stonecoil_Serpent | Glass_Casket | Henge_Walker | Roving_Keep | Witch's_Vengeance | Piper_of_the_Swarm | Steelgaze_Griffin | Scorching_Dragonfire | Lucky_Clover | Outmuscle | Lost_Legion | Emry_Lurker_of_the_Loch | Syr_Elenora_the_Discerning | Brazen_Borrower |
| 48 | Animating_Faerie | Linden_the_Steadfast_Queen | Mantle_of_Tides | Smitten_Swordmaster | Rally_for_the_Throne | Witch's_Cottage | Witching_Well | Tall_as_a_Beanstalk | Beanstalk_Giant | Mad_Ratter | Outflank | Locthwain_Paladin | Order_of_Midnight | Lost_Legion | Reave_Soul |
| 49 | Rosethorn_Acolyte | All_That_Glitters | Oko_Thief_of_Crowns | Sporecap_Spider | Shambling_Suit | Insatiable_Appetite | Archon_of_Absolution | Deafening_Silence | Hushbringer | Barrow_Witches | Venerable_Knight | Brazen_Borrower | Gingerbread_Cabin | Cauldron's_Gift | Sundering_Stroke |
| 50 | Oakhame_Ranger | Emry_Lurker_of_the_Loch | Improbable_Alliance | Bake_into_a_Pie | Deathless_Knight | Lucky_Clover | Golden_Egg | Skullknocker_Ogre | Rimrock_Knight | Worthy_Knight | Youthful_Knight | Prized_Griffin | Golden_Egg | Turn_into_a_Pumpkin | Clockwork_Servant |
| 51 | Tournament_Grounds | Weaselback_Redcap | Cauldron_Familiar | Murderous_Rider | Fortifying_Provisions | Reaper_of_Night | Ayara_First_of_Locthwain | Joust | Outmuscle | Wintermoor_Commander | Once_and_Future | Knight_of_the_Keep | Stonecoil_Serpent | Festive_Funeral | Covetous_Urge |
| 52 | Garruk_Cursed_Huntsman | Animating_Faerie | Turn_into_a_Pumpkin | Gingerbread_Cabin | Bartered_Cow | The_Cauldron_of_Eternity | Enchanted_Carriage | Giant's_Skewer | Tall_as_a_Beanstalk | Deathless_Knight | Acclaimed_Contender | Tournament_Grounds | Foulmire_Knight | Moonlit_Scavengers | Thrill_of_Possibility |
| 53 | Steelgaze_Griffin | Maraleaf_Pixie | Overwhelmed_Apprentice | Oathsworn_Knight | True_Love's_Kiss | Shambling_Suit | Scalding_Cauldron | Outlaws'_Merriment | Searing_Barrage | The_Magic_Mirror | Rally_for_the_Throne | Wicked_Guardian | Kenrith's_Transformation | The_Magic_Mirror | Spinning_Wheel |
| 54 | So_Tiny | Mysterious_Pathlighter | Hypnotic_Sprite | Enchanted_Carriage | Shepherd_of_the_Flock | Festive_Funeral | Clackbridge_Troll | Return_to_Nature | Fling | Cauldron's_Gift | Syr_Faren_the_Hengehammer | Silverflame_Squire | Resolute_Rider | Mystical_Dispute | Frogify |
| 55 | Lochmere_Serpent | Castle_Embereth | Bartered_Cow | Rosethorn_Halberd | Golden_Egg | Barrow_Witches | Folio_of_Fancies | Bonecrusher_Giant | Bloodhaze_Wolverine | Merchant_of_the_Vale | Trail_of_Crumbs | Righteousness | Malevolent_Noble | Forever_Young | Steelgaze_Griffin |
| 56 | Opt | Castle_Ardenvale | Flutterfox | Belle_of_the_Brawl | Emry_Lurker_of_the_Loch | All_That_Glitters | Frogify | Mistford_River_Turtle | Fierce_Witchstalker | Ogre_Errant | Return_of_the_Wildspeaker | Idyllic_Grange | Oathsworn_Knight | Corridor_Monitor | Forever_Young |
| 57 | Unexplained_Vision | Scalding_Cauldron | Sage_of_the_Falls | Foulmire_Knight | Barrow_Witches | Didn't_Say_Please | Into_the_Story | Righteousness | Wishclaw_Talisman | Edgewall_Innkeeper | Stonecoil_Serpent | Foreboding_Fruit | Faeburrow_Elder | Memory_Theft | Trapped_in_the_Tower |
| 58 | Kenrith's_Transformation | Shepherd_of_the_Flock | Syr_Elenora_the_Discerning | Tempting_Witch | Faeburrow_Elder | Questing_Beast | Fireborn_Knight | Shining_Armor | Syr_Carah_the_Bold | Improbable_Alliance | Castle_Garenbrig | Wishclaw_Talisman | Blacklance_Paragon | Locthwain_Paladin | Opportunistic_Dragon |
| 59 | Edgewall_Innkeeper | Faerie_Guidemother | Witching_Well | Maraleaf_Rider | Outmuscle | Wintermoor_Commander | Unexplained_Vision | Specter's_Shriek | Once_and_Future | Redcap_Melee | Garenbrig_Paladin | Ardenvale_Paladin | Syr_Faren_the_Hengehammer | Unexplained_Vision | Bake_into_a_Pie |
| 60 | Mystical_Dispute | Embereth_Paladin | Witch's_Oven | Clockwork_Servant | Garruk_Cursed_Huntsman | Locthwain_Gargoyle | Henge_Walker | Giant_Opportunity | Thunderous_Snapper | Resolute_Rider | Silverflame_Ritual | Festive_Funeral | Rosethorn_Acolyte | Belle_of_the_Brawl | Lochmere_Serpent |
| 61 | Once_and_Future | Witch's_Oven | Claim_the_Firstborn | Insatiable_Appetite | Smitten_Swordmaster | Mirrormade | Murderous_Rider | Robber_of_the_Rich | Irencrag_Pyromancer | Faeburrow_Elder | Kenrith's_Transformation | Bog_Naughty | Fabled_Passage | Oathsworn_Knight | Castle_Vantress |
| 62 | Wintermoor_Commander | Silverflame_Squire | Giant_Opportunity | Trapped_in_the_Tower | Spinning_Wheel | Weapon_Rack | Giant_Killer | Maraleaf_Pixie | Flaxen_Intruder | Loch_Dragon | The_Royal_Scions | Return_of_the_Wildspeaker | Garenbrig_Paladin | Wishful_Merfolk | Bloodhaze_Wolverine |
| 63 | Moonlit_Scavengers | Lucky_Clover | Irencrag_Pyromancer | Golden_Egg | Beloved_Princess | Syr_Faren_the_Hengehammer | Linden_the_Steadfast_Queen | Knight_of_the_Keep | Sorcerous_Spyglass | Specter's_Shriek | Savvy_Hunter | Silverflame_Ritual | Sporecap_Spider | Tome_Raider | Revenge_of_Ravens |
| 64 | Mistford_River_Turtle | Barge_In | Opt | Heraldic_Banner | Elite_Headhunter | Wicked_Guardian | Trapped_in_the_Tower | Faerie_Vandal | Loch_Dragon | Rimrock_Knight | True_Love's_Kiss | Syr_Elenora_the_Discerning | Forever_Young | Mirrormade | Gingerbread_Cabin |
| 65 | Arcanist's_Owl | Heraldic_Banner | Shepherd_of_the_Flock | Flutterfox | Lost_Legion | Wolf's_Quarry | Embereth_Shieldbreaker | True_Love's_Kiss | Sporecap_Spider | Locthwain_Paladin | Improbable_Alliance | Cauldron's_Gift | Enchanted_Carriage | Cauldron_Familiar | Fae_of_Wishes |
| 66 | Maraleaf_Rider | Loch_Dragon | Into_the_Story | Wicked_Guardian | Garenbrig_Paladin | Brazen_Borrower | Heraldic_Banner | Memory_Theft | Drown_in_the_Loch | Outlaws'_Merriment | Righteousness | Malevolent_Noble | Spinning_Wheel | Mystic_Sanctuary | Foreboding_Fruit |
| 67 | Mirrormade | Folio_of_Fancies | Shining_Armor | Brazen_Borrower | Belle_of_the_Brawl | Maraleaf_Rider | So_Tiny | Idyllic_Grange | Dance_of_the_Manse | Bake_into_a_Pie | Ardenvale_Paladin | Grumgully_the_Generous | Folio_of_Fancies | Specter's_Shriek | Witch's_Oven |
| 68 | Tuinvale_Treefolk | Dance_of_the_Manse | True_Love's_Kiss | Wildwood_Tracker | Dwarven_Mine | Fierce_Witchstalker | Seven_Dwarves | Bartered_Cow | Tuinvale_Treefolk | Lost_Legion | Fireborn_Knight | Mysterious_Pathlighter | Clockwork_Servant | Elite_Headhunter | Enchanted_Carriage |
| 69 | Deathless_Knight | Sorcerer's_Broom | Faerie_Vandal | Barrow_Witches | Vantress_Paladin | Raging_Redcap | Epic_Downfall | Torbran_Thane_of_Red_Fell | Ogre_Errant | Thrill_of_Possibility | Beloved_Princess | Inspiring_Veteran | Lost_Legion | Steelclaw_Lance | Tempting_Witch |
| 70 | Witching_Well | Merfolk_Secretkeeper | Flaxen_Intruder | Hypnotic_Sprite | Hushbringer | Fervent_Champion | Bog_Naughty | Redcap_Melee | Insatiable_Appetite | Sorcerous_Spyglass | Bonecrusher_Giant | Lonesome_Unicorn | Reaper_of_Night | Mistford_River_Turtle | Outmuscle |
| 71 | The_Magic_Mirror | Hushbringer | Specter's_Shriek | Redcap_Melee | Inquisitive_Puppet | Inquisitive_Puppet | Bake_into_a_Pie | Silverflame_Ritual | Mirrormade | Inspiring_Veteran | Grumgully_the_Generous | Shining_Armor | Irencrag_Pyromancer | Sage_of_the_Falls | Mantle_of_Tides |
| 72 | The_Circle_of_Loyalty | Shining_Armor | Archon_of_Absolution | Spinning_Wheel | Embereth_Paladin | Weaselback_Redcap | Burning-Yard_Trainer | Ardenvale_Paladin | Fabled_Passage | Acclaimed_Contender | Inspiring_Veteran | Specter's_Shriek | Maraleaf_Rider | Wicked_Guardian | Sporecap_Spider |
| 73 | Trail_of_Crumbs | Redcap_Raiders | Locthwain_Gargoyle | Steelclaw_Lance | Covetous_Urge | Run_Away_Together | Vantress_Paladin | Flaxen_Intruder | Rosethorn_Acolyte | Weaselback_Redcap | Idyllic_Grange | Flutterfox | Wicked_Guardian | Opt | Order_of_Midnight |
| 74 | Giant_Opportunity | Brazen_Borrower | The_Circle_of_Loyalty | Flaxen_Intruder | Searing_Barrage | Gingerbread_Cabin | Run_Away_Together | Gingerbread_Cabin | Happily_Ever_After | Fireborn_Knight | Maraleaf_Rider | Arcanist's_Owl | Cauldron's_Gift | Smitten_Swordmaster | Reaper_of_Night |
| 75 | Sporecap_Spider | Lonesome_Unicorn | Wishful_Merfolk | Faerie_Vandal | Wicked_Guardian | Faerie_Guidemother | Resolute_Rider | Locthwain_Paladin | Redcap_Melee | Searing_Barrage | Doom_Foretold | Wildborn_Preserver | Midnight_Clock | Maraleaf_Pixie | Improbable_Alliance |
| 76 | Rampart_Smasher | Grumgully_the_Generous | Weapon_Rack | Mysterious_Pathlighter | Garenbrig_Carver | Specter's_Shriek | Glass_Casket | Vantress_Paladin | Blow_Your_House_Down | Revenge_of_Ravens | Fell_the_Pheasant | Shinechaser | Escape_to_the_Wilds | Foreboding_Fruit | Memory_Theft |
| 77 | Fervent_Champion | Outflank | Castle_Embereth | Return_to_Nature | Syr_Faren_the_Hengehammer | Once_Upon_a_Time | Castle_Vantress | Mystical_Dispute | Joust | Reaper_of_Night | Giant_Opportunity | Witch's_Cottage | Oakhame_Ranger | Faerie_Vandal | Redcap_Raiders |
| 78 | Mystic_Sanctuary | Clockwork_Servant | Moonlit_Scavengers | Glass_Casket | Blacklance_Paragon | Flaxen_Intruder | Spinning_Wheel | Sundering_Stroke | Wolf's_Quarry | Scorching_Dragonfire | Return_to_Nature | Escape_to_the_Wilds | Belle_of_the_Brawl | Torbran_Thane_of_Red_Fell | Fierce_Witchstalker |
| 79 | Wildwood_Tracker | Belle_of_the_Brawl | Escape_to_the_Wilds | Elite_Headhunter | Witch's_Cottage | Gilded_Goose | Mysterious_Pathlighter | Eye_Collector | Inquisitive_Puppet | Raging_Redcap | All_That_Glitters | Forever_Young | Festive_Funeral | Wishclaw_Talisman | Prophet_of_the_Peak |
| 80 | Acclaimed_Contender | Prized_Griffin | Steelgaze_Griffin | Foreboding_Fruit | Sporecap_Spider | Mantle_of_Tides | Shinechaser | Rosethorn_Halberd | The_Royal_Scions | Wicked_Guardian | Sporecap_Spider | Memory_Theft | Improbable_Alliance | Lash_of_Thorns | Vantress_Paladin |
| 81 | Blacklance_Paragon | Silverflame_Ritual | Mystic_Sanctuary | Turn_into_a_Pumpkin | All_That_Glitters | Steelclaw_Lance | The_Circle_of_Loyalty | Burning-Yard_Trainer | Wandermare | Castle_Garenbrig | Arcanist's_Owl | Syr_Faren_the_Hengehammer | Rampart_Smasher | Malevolent_Noble | Dwarven_Mine |
| 82 | Rosethorn_Halberd | Enchanted_Carriage | Mistford_River_Turtle | Syr_Konrad_the_Grim | Garenbrig_Squire | Ferocity_of_the_Wilds | Oathsworn_Knight | Fortifying_Provisions | Embereth_Paladin | Castle_Vantress | Insatiable_Appetite | Happily_Ever_After | Drown_in_the_Loch | Barrow_Witches | Inspiring_Veteran |
| 83 | Garenbrig_Carver | Gingerbrute | Fervent_Champion | Stolen_by_the_Fae | Thunderous_Snapper | Crashing_Drawbridge | Syr_Alin_the_Lion's_Claw | Maraleaf_Rider | Doom_Foretold | Folio_of_Fancies | Garruk_Cursed_Huntsman | Tempting_Witch | Scalding_Cauldron | Clockwork_Servant | Witch's_Cottage |
| 84 | Flaxen_Intruder | Ardenvale_Paladin | Gingerbrute | Fell_the_Pheasant | Burning-Yard_Trainer | Beloved_Princess | Moonlit_Scavengers | Savvy_Hunter | Henge_Walker | Flaxen_Intruder | Wildwood_Tracker | Deafening_Silence | Acclaimed_Contender | Garruk_Cursed_Huntsman | Wicked_Guardian |
| 85 | Wishful_Merfolk | Rally_for_the_Throne | Tournament_Grounds | Wolf's_Quarry | Crystal_Slipper | Edgewall_Innkeeper | Redcap_Raiders | Mystic_Sanctuary | Eye_Collector | Fling | Merchant_of_the_Vale | Steelclaw_Lance | Giant's_Skewer | Witch's_Cottage | Festive_Funeral |
| 86 | Grumgully_the_Generous | Midnight_Clock | Thunderous_Snapper | Tall_as_a_Beanstalk | Steelgaze_Griffin | Tuinvale_Treefolk | Mirrormade | Weapon_Rack | Fell_the_Pheasant | Reave_Soul | Bartered_Cow | Gadwick_the_Wizened | Mad_Ratter | Edgewall_Innkeeper | Foulmire_Knight |
| 87 | Tall_as_a_Beanstalk | Wintermoor_Commander | Ayara_First_of_Locthwain | Queen_of_Ice | Stonecoil_Serpent | Jousting_Dummy | Joust | Festive_Funeral | Elite_Headhunter | Forever_Young | Knight_of_the_Keep | Joust | Sundering_Stroke | Wandermare | Curious_Pair |
| 88 | Covetous_Urge | Ferocity_of_the_Wilds | Mysterious_Pathlighter | Blacklance_Paragon | Ogre_Errant | Garenbrig_Carver | Castle_Embereth | Cauldron_Familiar | Return_to_Nature | Dance_of_the_Manse | Rampart_Smasher | True_Love's_Kiss | Witch's_Cottage | Stonecoil_Serpent | Piper_of_the_Swarm |
| 89 | Steelclaw_Lance | Crystal_Slipper | Silverflame_Ritual | Redcap_Raiders | The_Great_Henge | Castle_Locthwain | Order_of_Midnight | Venerable_Knight | Lochmere_Serpent | Emry_Lurker_of_the_Loch | Tall_as_a_Beanstalk | Fortifying_Provisions | Fell_the_Pheasant | Giant's_Skewer | Trail_of_Crumbs |
| 90 | Garenbrig_Squire | Knight_of_the_Keep | Wandermare | Silverflame_Squire | Malevolent_Noble | Keeper_of_Fables | Charming_Prince | Unexplained_Vision | Fireborn_Knight | Dwarven_Mine | Resolute_Rider | Reaper_of_Night | Dance_of_the_Manse | Steelgaze_Griffin | Roving_Keep |
| 91 | Stonecoil_Serpent | Fabled_Passage | Roving_Keep | Clackbridge_Troll | Embercleave | Sorcerer's_Broom | Gilded_Goose | Belle_of_the_Brawl | Gingerbrute | Crystal_Slipper | Irencrag_Pyromancer | Lash_of_Thorns | Covetous_Urge | Mantle_of_Tides | Malevolent_Noble |
| 92 | Improbable_Alliance | Jousting_Dummy | Skullknocker_Ogre | Shepherd_of_the_Flock | Corridor_Monitor | Shining_Armor | Reave_Soul | Roving_Keep | Crystal_Slipper | Fae_of_Wishes | Fabled_Passage | Castle_Vantress | Return_to_Nature | Shinechaser | Sorcerer's_Broom |
| 93 | Fabled_Passage | Trail_of_Crumbs | Oakhame_Ranger | Syr_Elenora_the_Discerning | Scorching_Dragonfire | Embercleave | Ardenvale_Tactician | Garenbrig_Squire | Garenbrig_Carver | Stonecoil_Serpent | Reaper_of_Night | Bartered_Cow | Castle_Ardenvale | Dance_of_the_Manse | Brimstone_Trebuchet |
| 94 | Curious_Pair | Golden_Egg | Wintermoor_Commander | Charmed_Sleep | Joust | Golden_Egg | Syr_Konrad_the_Grim | Tome_Raider | Thrill_of_Possibility | Lochmere_Serpent | Fortifying_Provisions | Stolen_by_the_Fae | Wolf's_Quarry | Tempting_Witch | Crashing_Drawbridge |
| 95 | Faeburrow_Elder | Claim_the_Firstborn | Unexplained_Vision | Moonlit_Scavengers | Once_Upon_a_Time | Henge_Walker | Blacklance_Paragon | Lost_Legion | Mad_Ratter | Witch's_Cottage | Rosethorn_Halberd | Faerie_Guidemother | Insatiable_Appetite | Irencrag_Feat | Embereth_Shieldbreaker |
| 96 | Emry_Lurker_of_the_Loch | Blacklance_Paragon | Castle_Locthwain | Savvy_Hunter | Festive_Funeral | Embereth_Paladin | The_Magic_Mirror | Curious_Pair | Vantress_Gargoyle | Midnight_Clock | Gingerbread_Cabin | Stormfist_Crusader | The_Royal_Scions | Fires_of_Invention | Rimrock_Knight |
| 97 | Belle_of_the_Brawl | Spinning_Wheel | Vantress_Paladin | Fabled_Passage | Rosethorn_Halberd | Rimrock_Knight | Rimrock_Knight | Wildwood_Tracker | Overwhelmed_Apprentice | Cauldron_Familiar | Oko_Thief_of_Crowns | Questing_Beast | Edgewall_Innkeeper | Locthwain_Gargoyle | Once_and_Future |
| 98 | Joust | Hypnotic_Sprite | Ardenvale_Paladin | Seven_Dwarves | Torbran_Thane_of_Red_Fell | Silverflame_Ritual | Revenge_of_Ravens | Happily_Ever_After | Shinechaser | Festive_Funeral | Wintermoor_Commander | Oakhame_Ranger | Linden_the_Steadfast_Queen | Sorcerous_Spyglass | Return_to_Nature |
| 99 | Gingerbread_Cabin | Skullknocker_Ogre | Heraldic_Banner | Tome_Raider | Weaselback_Redcap | Return_to_Nature | Thunderous_Snapper | Cauldron's_Gift | Emry_Lurker_of_the_Loch | Blow_Your_House_Down | Folio_of_Fancies | Enchanted_Carriage | Doom_Foretold | Fabled_Passage | Fell_the_Pheasant |
| 100 | Locthwain_Paladin | Resolute_Rider | Ferocity_of_the_Wilds | Archon_of_Absolution | Rosethorn_Acolyte | Shinechaser | Ferocity_of_the_Wilds | Sorcerous_Spyglass | Giant_Opportunity | Drown_in_the_Loch | Sundering_Stroke | Eye_Collector | Shambling_Suit | Oko_Thief_of_Crowns | Fling |
| 101 | Mantle_of_Tides | Fling | Knight_of_the_Keep | Embereth_Shieldbreaker | Yorvo_Lord_of_Garenbrig | Sporecap_Spider | Mantle_of_Tides | Sage_of_the_Falls | Heraldic_Banner | Deafening_Silence | Happily_Ever_After | Fireborn_Knight | Tuinvale_Treefolk | Gingerbrute | Syr_Konrad_the_Grim |
| 102 | Fell_the_Pheasant | Order_of_Midnight | Venerable_Knight | Witch's_Cottage | Foreboding_Fruit | Fell_the_Pheasant | Shepherd_of_the_Flock | Wandermare | Deafening_Silence | Heraldic_Banner | Escape_to_the_Wilds | Redcap_Melee | Maraleaf_Pixie | Heraldic_Banner | Henge_Walker |
| 103 | Heraldic_Banner | Run_Away_Together | Stonecoil_Serpent | Revenge_of_Ravens | Sorcerer's_Broom | Wildborn_Preserver | Flutterfox | Trail_of_Crumbs | Shambling_Suit | Mirrormade | Fires_of_Invention | Hypnotic_Sprite | Sorcerous_Spyglass | Witch's_Oven | Idyllic_Grange |
| 104 | Jousting_Dummy | Merchant_of_the_Vale | Cauldron's_Gift | Weapon_Rack | Maraleaf_Rider | Linden_the_Steadfast_Queen | Shambling_Suit | Witch's_Cottage | Locthwain_Gargoyle | Foreboding_Fruit | Foulmire_Knight | Yorvo_Lord_of_Garenbrig | Castle_Vantress | Enchanted_Carriage | Ogre_Errant |
| 105 | Wandermare | Epic_Downfall | Queen_of_Ice | Prophet_of_the_Peak | Merchant_of_the_Vale | Bloodhaze_Wolverine | Syr_Faren_the_Hengehammer | Tuinvale_Treefolk | Burning-Yard_Trainer | The_Circle_of_Loyalty | Revenge_of_Ravens | Faeburrow_Elder | Specter's_Shriek | Flaxen_Intruder | Grumgully_the_Generous |
| 106 | Oathsworn_Knight | Smitten_Swordmaster | Prized_Griffin | Sage_of_the_Falls | Righteousness | Fortifying_Provisions | Witch's_Vengeance | Smitten_Swordmaster | Merchant_of_the_Vale | Savvy_Hunter | Fae_of_Wishes | Beloved_Princess | The_Circle_of_Loyalty | Faeburrow_Elder | Silverflame_Squire |
| 107 | Return_to_Nature | Mirrormade | Syr_Alin_the_Lion's_Claw | Fae_of_Wishes | Forever_Young | Crystal_Slipper | Brimstone_Trebuchet | Gingerbrute | Specter's_Shriek | Covetous_Urge | Wolf's_Quarry | Spinning_Wheel | Locthwain_Paladin | Prophet_of_the_Peak | Blow_Your_House_Down |
| 108 | Insatiable_Appetite | Fortifying_Provisions | Wolf's_Quarry | Witch's_Vengeance | Tuinvale_Treefolk | Yorvo_Lord_of_Garenbrig | Tempting_Witch | Youthful_Knight | Outlaws'_Merriment | Ferocity_of_the_Wilds | Didn't_Say_Please | Outlaws'_Merriment | Tournament_Grounds | Garenbrig_Carver | Bartered_Cow |
| 109 | Corridor_Monitor | Dwarven_Mine | Idyllic_Grange | Signpost_Scarecrow | Fierce_Witchstalker | The_Circle_of_Loyalty | Malevolent_Noble | Frogify | Castle_Vantress | Lash_of_Thorns | Deafening_Silence | Charmed_Sleep | Robber_of_the_Rich | Arcanist's_Owl | Flutterfox |
| 110 | Spinning_Wheel | Wildborn_Preserver | Once_Upon_a_Time | Grumgully_the_Generous | Reaper_of_Night | Oko_Thief_of_Crowns | Witch's_Oven | Corridor_Monitor | Deathless_Knight | Wandermare | Mad_Ratter | Into_the_Story | Irencrag_Feat | All_That_Glitters | Barge_In |
| 111 | Weaselback_Redcap | Foulmire_Knight | Loch_Dragon | Barge_In | Reave_Soul | Garenbrig_Paladin | Questing_Beast | Faerie_Guidemother | Garenbrig_Squire | Once_Upon_a_Time | Queen_of_Ice | Vantress_Gargoyle | Flaxen_Intruder | Inquisitive_Puppet | Archon_of_Absolution |
| 112 | Ardenvale_Paladin | Stolen_by_the_Fae | Spinning_Wheel | Castle_Garenbrig | Ayara_First_of_Locthwain | Heraldic_Banner | Ogre_Errant | Barrow_Witches | Castle_Locthwain | Inquisitive_Puppet | Enchanted_Carriage | Elite_Headhunter | Seven_Dwarves | Crashing_Drawbridge | Outflank |
| 113 | Raging_Redcap | So_Tiny | Worthy_Knight | Oakhame_Ranger | Syr_Carah_the_Bold | Opt | Grumgully_the_Generous | Reaper_of_Night | Gingerbread_Cabin | Castle_Ardenvale | Brazen_Borrower | Fabled_Passage | Realm-Cloaked_Giant | Shambling_Suit | Locthwain_Gargoyle |
| 114 | Smitten_Swordmaster | Giant_Opportunity | Tome_Raider | Reaper_of_Night | Feasting_Troll_King | Roving_Keep | Didn't_Say_Please | Forever_Young | Embereth_Shieldbreaker | Bloodhaze_Wolverine | Cauldron_Familiar | Ferocity_of_the_Wilds | Worthy_Knight | Resolute_Rider | Ardenvale_Tactician |
| 115 | Venerable_Knight | Reave_Soul | Didn't_Say_Please | Giant's_Skewer | Mystic_Sanctuary | Steelgaze_Griffin | Belle_of_the_Brawl | Witching_Well | Fae_of_Wishes | Memory_Theft | Overwhelmed_Apprentice | Syr_Carah_the_Bold | Fireborn_Knight | Mysterious_Pathlighter | Skullknocker_Ogre |
| 116 | Ogre_Errant | Wicked_Wolf | Outflank | Joust | Rampart_Smasher | Folio_of_Fancies | Wildborn_Preserver | Garenbrig_Carver | Castle_Ardenvale | Spinning_Wheel | Slaying_Fire | Giant's_Skewer | Heraldic_Banner | Tuinvale_Treefolk | True_Love's_Kiss |
| 117 | Brimstone_Trebuchet | Blow_Your_House_Down | Stormfist_Crusader | Mantle_of_Tides | Moonlit_Scavengers | Youthful_Knight | Fabled_Passage | Tempting_Witch | The_Cauldron_of_Eternity | Malevolent_Noble | The_Magic_Mirror | Outmuscle | Memory_Theft | Roving_Keep | Witch's_Vengeance |
| 118 | Drown_in_the_Loch | Turn_into_a_Pumpkin | Faerie_Guidemother | Roving_Keep | Oakhame_Adversary | Ardenvale_Tactician | Savvy_Hunter | Prized_Griffin | Rally_for_the_Throne | Sorcerer's_Broom | Hypnotic_Sprite | Fierce_Witchstalker | Wintermoor_Commander | Faerie_Guidemother | Mirrormade |
| 119 | Syr_Carah_the_Bold | Syr_Konrad_the_Grim | Prophet_of_the_Peak | Jousting_Dummy | Tall_as_a_Beanstalk | Queen_of_Ice | Raging_Redcap | Bog_Naughty | All_That_Glitters | Barge_In | Shining_Armor | Turn_into_a_Pumpkin | Elite_Headhunter | Rosethorn_Acolyte | Joust |
| 120 | Knight_of_the_Keep | Outmuscle | Signpost_Scarecrow | Embercleave | Wishful_Merfolk | Garenbrig_Squire | Worthy_Knight | Sporecap_Spider | Clockwork_Servant | Yorvo_Lord_of_Garenbrig | Witch's_Oven | Raging_Redcap | Garenbrig_Carver | Weapon_Rack | Garenbrig_Squire |
| 121 | Savvy_Hunter | Righteousness | Kenrith's_Transformation | Castle_Locthwain | Giant's_Skewer | Kenrith's_Transformation | Sorcerer's_Broom | Lonesome_Unicorn | Ayara_First_of_Locthwain | Redcap_Raiders | Maraleaf_Pixie | Gilded_Goose | Stormfist_Crusader | Once_Upon_a_Time | Emry_Lurker_of_the_Loch |
| 122 | Wolf's_Quarry | Fierce_Witchstalker | Charmed_Sleep | Lost_Legion | Raging_Redcap | Faerie_Vandal | Lovestruck_Beast | Oko_Thief_of_Crowns | Righteousness | Jousting_Dummy | Rimrock_Knight | Redcap_Raiders | Wandermare | Spinning_Wheel | Escape_to_the_Wilds |
| 123 | Escape_to_the_Wilds | Thrill_of_Possibility | Run_Away_Together | Rimrock_Knight | Unexplained_Vision | Flutterfox | Outmuscle | Foreboding_Fruit | Roving_Keep | Giant's_Skewer | Run_Away_Together | Scorching_Dragonfire | Fires_of_Invention | Beanstalk_Giant | Clackbridge_Troll |
| 124 | Fires_of_Invention | Rankle_Master_of_Pranks | Trapped_in_the_Tower | Scorching_Dragonfire | Fabled_Passage | Harmonious_Archon | Feasting_Troll_King | Queen_of_Ice | Crashing_Drawbridge | Signpost_Scarecrow | Robber_of_the_Rich | Tome_Raider | Happily_Ever_After | Sorcerer's_Broom | Eye_Collector |
| 125 | Embereth_Paladin | Overwhelmed_Apprentice | So_Tiny | Gingerbrute | Murderous_Rider | Mystical_Dispute | Fierce_Witchstalker | Rosethorn_Acolyte | Enchanted_Carriage | Garenbrig_Carver | Stolen_by_the_Fae | Faerie_Vandal | Signpost_Scarecrow | Prized_Griffin | Maraleaf_Rider |
| 126 | Shining_Armor | Bake_into_a_Pie | Tall_as_a_Beanstalk | Searing_Barrage | Mistford_River_Turtle | Claim_the_Firstborn | Mystic_Sanctuary | Didn't_Say_Please | Into_the_Story | Charming_Prince | Forever_Young | Wildwood_Tracker | Opportunistic_Dragon | Opportunistic_Dragon | Prized_Griffin |
| 127 | Lost_Legion | Charmed_Sleep | Clockwork_Servant | Locthwain_Paladin | Memory_Theft | Lochmere_Serpent | Dwarven_Mine | Malevolent_Noble | Stonecoil_Serpent | Shambling_Suit | Dance_of_the_Manse | Deathless_Knight | The_Magic_Mirror | Deafening_Silence | Garenbrig_Paladin |
| 128 | Crashing_Drawbridge | Cauldron_Familiar | The_Cauldron_of_Eternity | Bartered_Cow | Lovestruck_Beast | Rosethorn_Acolyte | Castle_Ardenvale | Fireborn_Knight | Mystical_Dispute | Rampart_Smasher | Castle_Locthwain | Fae_of_Wishes | Prophet_of_the_Peak | Brimstone_Trebuchet | Wolf's_Quarry |
| 129 | Stormfist_Crusader | Crashing_Drawbridge | Lonesome_Unicorn | All_That_Glitters | Gingerbread_Cabin | Syr_Alin_the_Lion's_Claw | Deathless_Knight | Moonlit_Scavengers | Brimstone_Trebuchet | Sage_of_the_Falls | Vantress_Gargoyle | Frogify | Redcap_Melee | Doom_Foretold | Jousting_Dummy |
| 130 | Outlaws'_Merriment | Fires_of_Invention | Golden_Egg | Skullknocker_Ogre | Fell_the_Pheasant | Tome_Raider | Gingerbrute | Jousting_Dummy | Frogify | Once_and_Future | Lochmere_Serpent | Scalding_Cauldron | Barrow_Witches | Jousting_Dummy | Fabled_Passage |
| 131 | Embereth_Shieldbreaker | Vantress_Gargoyle | Giant's_Skewer | Ferocity_of_the_Wilds | Slaying_Fire | Sorcerous_Spyglass | Oakhame_Ranger | Rally_for_the_Throne | Didn't_Say_Please | Righteousness | Spinning_Wheel | Castle_Embereth | Charming_Prince | Beloved_Princess | Deafening_Silence |
| 132 | Irencrag_Pyromancer | Murderous_Rider | Crashing_Drawbridge | Dwarven_Mine | Beanstalk_Giant | Inspiring_Veteran | Smitten_Swordmaster | The_Magic_Mirror | Folio_of_Fancies | Clockwork_Servant | Embercleave | Ogre_Errant | Grumgully_the_Generous | Scalding_Cauldron | Fortifying_Provisions |
| 133 | Rimrock_Knight | Weapon_Rack | Drown_in_the_Loch | Crashing_Drawbridge | Tournament_Grounds | Silverflame_Squire | Rally_for_the_Throne | Prophet_of_the_Peak | Prophet_of_the_Peak | Gadwick_the_Wizened | Sage_of_the_Falls | The_Magic_Mirror | Harmonious_Archon | Castle_Garenbrig | Crystal_Slipper |
| 134 | Youthful_Knight | Beloved_Princess | Enchanted_Carriage | Burning-Yard_Trainer | Witching_Well | Stormfist_Crusader | Wicked_Guardian | Inquisitive_Puppet | Cauldron's_Gift | Venerable_Knight | The_Cauldron_of_Eternity | Garenbrig_Paladin | Gingerbrute | Escape_to_the_Wilds | Youthful_Knight |
| 135 | Sorcerous_Spyglass | Idyllic_Grange | Fell_the_Pheasant | Sundering_Stroke | Return_to_Nature | Animating_Faerie | Keeper_of_Fables | Golden_Egg | Signpost_Scarecrow | Lonesome_Unicorn | Gadwick_the_Wizened | Skullknocker_Ogre | Brimstone_Trebuchet | Hushbringer | Lonesome_Unicorn |
| 136 | Scorching_Dragonfire | Oakhame_Ranger | Mad_Ratter | Stormfist_Crusader | The_Cauldron_of_Eternity | The_Royal_Scions | Foreboding_Fruit | Castle_Garenbrig | Savvy_Hunter | Vantress_Gargoyle | Witch's_Vengeance | Sage_of_the_Falls | Thunderous_Snapper | Fervent_Champion | Shambling_Suit |
| 137 | Prophet_of_the_Peak | Giant's_Skewer | Insatiable_Appetite | Lonesome_Unicorn | Charmed_Sleep | Barge_In | Lucky_Clover | Run_Away_Together | Weapon_Rack | Mysterious_Pathlighter | Deathless_Knight | Wicked_Wolf | Giant_Killer | Flutterfox | Bog_Naughty |
| 138 | Robber_of_the_Rich | Henge_Walker | Inspiring_Veteran | Blow_Your_House_Down | Rimrock_Knight | Lovestruck_Beast | Yorvo_Lord_of_Garenbrig | Locthwain_Gargoyle | Mystic_Sanctuary | Lovestruck_Beast | Searing_Barrage | Barge_In | Lash_of_Thorns | Oakhame_Adversary | Shepherd_of_the_Flock |
| 139 | Doom_Foretold | True_Love's_Kiss | Silverflame_Squire | Covetous_Urge | Keeper_of_Fables | Venerable_Knight | Overwhelmed_Apprentice | Silverflame_Squire | Wishful_Merfolk | Crashing_Drawbridge | Torbran_Thane_of_Red_Fell | Mystical_Dispute | Inquisitive_Puppet | Thunderous_Snapper | Dance_of_the_Manse |
| 140 | Signpost_Scarecrow | Frogify | Jousting_Dummy | Locthwain_Gargoyle | Embereth_Shieldbreaker | Return_of_the_Wildspeaker | Wicked_Wolf | Outflank | Realm-Cloaked_Giant | Kenrith's_Transformation | Faerie_Vandal | Rimrock_Knight | Crashing_Drawbridge | Tournament_Grounds | Glass_Casket |
| 141 | Golden_Egg | Didn't_Say_Please | Crystal_Slipper | Ardenvale_Tactician | Lash_of_Thorns | Ogre_Errant | Outlaws'_Merriment | Turn_into_a_Pumpkin | Spinning_Wheel | Enchanted_Carriage | So_Tiny | Cauldron_Familiar | Syr_Carah_the_Bold | Grumgully_the_Generous | Garenbrig_Carver |
| 142 | Syr_Alin_the_Lion's_Claw | Witching_Well | Trail_of_Crumbs | Mistford_River_Turtle | Seven_Dwarves | Burning-Yard_Trainer | Skullknocker_Ogre | So_Tiny | Harmonious_Archon | Mystical_Dispute | Drown_in_the_Loch | Robber_of_the_Rich | Glass_Casket | Return_to_Nature | Raging_Redcap |
| 143 | Lucky_Clover | Gadwick_the_Wizened | Return_to_Nature | Forever_Young | Thrill_of_Possibility | Vantress_Gargoyle | The_Cauldron_of_Eternity | Edgewall_Innkeeper | Beloved_Princess | Grumgully_the_Generous | Seven_Dwarves | Vantress_Paladin | Vantress_Gargoyle | The_Royal_Scions | The_Royal_Scions |
| 144 | Ardenvale_Tactician | Moonlit_Scavengers | Lash_of_Thorns | Prized_Griffin | Opportunistic_Dragon | Hypnotic_Sprite | Acclaimed_Contender | Kenrith's_Transformation | Midnight_Clock | Prophet_of_the_Peak | Opt | Savvy_Hunter | Torbran_Thane_of_Red_Fell | Rosethorn_Halberd | Specter's_Shriek |
| 145 | Henge_Walker | Oakhame_Adversary | Henge_Walker | Witching_Well | Bake_into_a_Pie | Blow_Your_House_Down | Silverflame_Squire | Crashing_Drawbridge | Memory_Theft | Hushbringer | Eye_Collector | Kenrith's_Transformation | Syr_Alin_the_Lion's_Claw | Righteousness | Insatiable_Appetite |
| 146 | Barrow_Witches | Inquisitive_Puppet | Blow_Your_House_Down | Cauldron_Familiar | Mantle_of_Tides | Wishclaw_Talisman | Corridor_Monitor | Hypnotic_Sprite | Festive_Funeral | Eye_Collector | Gingerbrute | Maraleaf_Rider | Castle_Embereth | Keeper_of_Fables | Rosethorn_Acolyte |
| 147 | Clockwork_Servant | Keeper_of_Fables | Fling | Frogify | Wildwood_Tracker | Ardenvale_Paladin | Hushbringer | Into_the_Story | Charming_Prince | Into_the_Story | Sorcerous_Spyglass | Slaying_Fire | Witching_Well | Happily_Ever_After | Beanstalk_Giant |
| 148 | Happily_Ever_After | Bartered_Cow | Resolute_Rider | Wishclaw_Talisman | Blow_Your_House_Down | Shepherd_of_the_Flock | Wandermare | Ardenvale_Tactician | Corridor_Monitor | Roving_Keep | Mystical_Dispute | Lovestruck_Beast | Into_the_Story | Claim_the_Firstborn | Thunderous_Snapper |
| 149 | Burning-Yard_Trainer | Oathsworn_Knight | Gingerbread_Cabin | Once_Upon_a_Time | So_Tiny | Outmuscle | Embereth_Paladin | Heraldic_Banner | Cauldron_Familiar | Shepherd_of_the_Flock | Claim_the_Firstborn | Irencrag_Feat | Hushbringer | Castle_Embereth | Embereth_Paladin |
| 150 | Enchanted_Carriage | Fae_of_Wishes | Once_and_Future | Outflank | Tome_Raider | Righteousness | Return_of_the_Wildspeaker | Foulmire_Knight | Mistford_River_Turtle | Return_of_the_Wildspeaker | Embereth_Shieldbreaker | Searing_Barrage | Smitten_Swordmaster | Realm-Cloaked_Giant | Tuinvale_Treefolk |
| 151 | Searing_Barrage | Revenge_of_Ravens | Youthful_Knight | Corridor_Monitor | Curious_Pair | Doom_Foretold | Youthful_Knight | Elite_Headhunter | Trail_of_Crumbs | Weapon_Rack | Order_of_Midnight | Maraleaf_Pixie | Garenbrig_Squire | Ferocity_of_the_Wilds | Faerie_Guidemother |
| 152 | Lash_of_Thorns | Queen_of_Ice | Rosethorn_Halberd | Ogre_Errant | Inspiring_Veteran | Prophet_of_the_Peak | Faeburrow_Elder | Wicked_Guardian | Edgewall_Innkeeper | Locthwain_Gargoyle | Thrill_of_Possibility | Dance_of_the_Manse | Searing_Barrage | True_Love's_Kiss | Claim_the_Firstborn |
| 153 | Foulmire_Knight | Lost_Legion | Eye_Collector | Bloodhaze_Wolverine | Insatiable_Appetite | Frogify | The_Great_Henge | Syr_Elenora_the_Discerning | Improbable_Alliance | Garenbrig_Squire | Bake_into_a_Pie | Bloodhaze_Wolverine | Trapped_in_the_Tower | Garenbrig_Squire | Outlaws'_Merriment |
| 154 | Righteousness | Syr_Elenora_the_Discerning | Covetous_Urge | Unexplained_Vision | Oathsworn_Knight | Stonecoil_Serpent | Fervent_Champion | Garenbrig_Paladin | Silverflame_Ritual | Tuinvale_Treefolk | Scorching_Dragonfire | All_That_Glitters | Turn_into_a_Pumpkin | Crystal_Slipper | Weapon_Rack |
| 155 | Castle_Embereth | Forever_Young | Dwarven_Mine | Ayara_First_of_Locthwain | Order_of_Midnight | Redcap_Raiders | Stormfist_Crusader | Once_Upon_a_Time | Stormfist_Crusader | Bog_Naughty | Opportunistic_Dragon | Queen_of_Ice | Sage_of_the_Falls | Redcap_Raiders | Knight_of_the_Keep |
| 156 | Crystal_Slipper | Barrow_Witches | Ardenvale_Tactician | Vantress_Paladin | Sorcerous_Spyglass | So_Tiny | Dance_of_the_Manse | The_Cauldron_of_Eternity | Curious_Pair | Rosethorn_Acolyte | Mirrormade | Garruk_Cursed_Huntsman | Moonlit_Scavengers | Castle_Ardenvale | Kenrith's_Transformation |
| 157 | Weapon_Rack | Prophet_of_the_Peak | Fireborn_Knight | Faerie_Guidemother | Syr_Konrad_the_Grim | Hushbringer | Weaselback_Redcap | Grumgully_the_Generous | Lash_of_Thorns | Beanstalk_Giant | Golden_Egg | Sporecap_Spider | Deafening_Silence | Fling | Lash_of_Thorns |
| 158 | Hushbringer | Thunderous_Snapper | Wildwood_Tracker | Crystal_Slipper | Sundering_Stroke | Loch_Dragon | Mystical_Dispute | Fierce_Witchstalker | Bartered_Cow | Golden_Egg | Smitten_Swordmaster | Burning-Yard_Trainer | Henge_Walker | Garenbrig_Paladin | Gilded_Goose |
| 159 | Slaying_Fire | Beanstalk_Giant | Memory_Theft | Dance_of_the_Manse | Wintermoor_Commander | The_Great_Henge | Barge_In | Castle_Vantress | Brazen_Borrower | Stolen_by_the_Fae | Midnight_Clock | Heraldic_Banner | So_Tiny | Blow_Your_House_Down | Barrow_Witches |
| 160 | Festive_Funeral | Corridor_Monitor | Lochmere_Serpent | Fortifying_Provisions | Bloodhaze_Wolverine | Fling | Foulmire_Knight | Doom_Foretold | Giant_Killer | Overwhelmed_Apprentice | Murderous_Rider | Bonecrusher_Giant | Unexplained_Vision | Embereth_Paladin | Robber_of_the_Rich |
| 161 | The_Cauldron_of_Eternity | Return_of_the_Wildspeaker | Lucky_Clover | Inquisitive_Puppet | Loch_Dragon | Oakhame_Adversary | Steelclaw_Lance | Castle_Ardenvale | Jousting_Dummy | Witch's_Oven | Redcap_Melee | Didn't_Say_Please | Archon_of_Absolution | Weaselback_Redcap | Burning-Yard_Trainer |
| 162 | Scalding_Cauldron | Escape_to_the_Wilds | Yorvo_Lord_of_Garenbrig | Cauldron's_Gift | Fling | The_Magic_Mirror | Faerie_Guidemother | Witch's_Oven | Archon_of_Absolution | Merfolk_Secretkeeper | Shinechaser | Keeper_of_Fables | Gadwick_the_Wizened | Skullknocker_Ogre | Weaselback_Redcap |
| 163 | Thrill_of_Possibility | Bog_Naughty | Robber_of_the_Rich | Memory_Theft | Epic_Downfall | Tournament_Grounds | Lonesome_Unicorn | Oakhame_Adversary | Witch's_Cottage | Scalding_Cauldron | Witching_Well | Insatiable_Appetite | Mirrormade | Charming_Prince | Lost_Legion |
| 164 | Giant's_Skewer | Once_and_Future | Return_of_the_Wildspeaker | Robber_of_the_Rich | Queen_of_Ice | Wishful_Merfolk | Oakhame_Adversary | Signpost_Scarecrow | Sage_of_the_Falls | Ardenvale_Paladin | Irencrag_Feat | Once_and_Future | Scorching_Dragonfire | Knight_of_the_Keep | Questing_Beast |
| 165 | Roving_Keep | Sorcerous_Spyglass | Merfolk_Secretkeeper | Festive_Funeral | Eye_Collector | Corridor_Monitor | Merfolk_Secretkeeper | Enchanted_Carriage | Merfolk_Secretkeeper | Knight_of_the_Keep | Bloodhaze_Wolverine | Steelgaze_Griffin | Rally_for_the_Throne | Lonesome_Unicorn | Wildwood_Tracker |
| 166 | Sundering_Stroke | Locthwain_Gargoyle | Bloodhaze_Wolverine | Run_Away_Together | Lucky_Clover | Witching_Well | Mistford_River_Turtle | Charmed_Sleep | Wicked_Guardian | True_Love's_Kiss | Castle_Embereth | Rosethorn_Halberd | Mystic_Sanctuary | Loch_Dragon | Silverflame_Ritual |
| 167 | Irencrag_Feat | Syr_Faren_the_Hengehammer | Thrill_of_Possibility | Opportunistic_Dragon | Kenrith's_Transformation | Signpost_Scarecrow | Beanstalk_Giant | Once_and_Future | Mantle_of_Tides | All_That_Glitters | Syr_Carah_the_Bold | Weaselback_Redcap | Bonecrusher_Giant | Ardenvale_Paladin | Oakhame_Adversary |
| 168 | Forever_Young | Irencrag_Feat | Witch's_Cottage | Fling | Clackbridge_Troll | Mystic_Sanctuary | Locthwain_Paladin | Bake_into_a_Pie | Revenge_of_Ravens | Sporecap_Spider | Charmed_Sleep | Oakhame_Adversary | Fervent_Champion | Tall_as_a_Beanstalk | Shining_Armor |
| 169 | Silverflame_Ritual | Garenbrig_Paladin | Savvy_Hunter | Lash_of_Thorns | Barge_In | Knight_of_the_Keep | Castle_Locthwain | Spinning_Wheel | Idyllic_Grange | Henge_Walker | Unexplained_Vision | Claim_the_Firstborn | Steelclaw_Lance | Rimrock_Knight | Realm-Cloaked_Giant |
| 170 | Inquisitive_Puppet | Curious_Pair | Tempting_Witch | Arcanist's_Owl | Tempting_Witch | Thrill_of_Possibility | Prized_Griffin | Reave_Soul | Steelgaze_Griffin | Mystic_Sanctuary | Cauldron's_Gift | Blow_Your_House_Down | Slaying_Fire | Shepherd_of_the_Flock | Ferocity_of_the_Wilds |
| 171 | Syr_Konrad_the_Grim | Tempting_Witch | Curious_Pair | Steelgaze_Griffin | Opt | Gadwick_the_Wizened | Edgewall_Innkeeper | Castle_Locthwain | Vantress_Paladin | Return_to_Nature | Fling | Fires_of_Invention | Tall_as_a_Beanstalk | Robber_of_the_Rich | Giant_Killer |
| 172 | Merchant_of_the_Vale | Feasting_Troll_King | Gilded_Goose | Merchant_of_the_Vale | Cauldron's_Gift | Worthy_Knight | Trail_of_Crumbs | Mysterious_Pathlighter | Outflank | Unexplained_Vision | Mystic_Sanctuary | Sundering_Stroke | Corridor_Monitor | Barge_In | The_Magic_Mirror |
| 173 | Blow_Your_House_Down | Lovestruck_Beast | Barge_In | Emry_Lurker_of_the_Loch | Redcap_Raiders | Beanstalk_Giant | Prophet_of_the_Peak | Beanstalk_Giant | Sorcerer's_Broom | Maraleaf_Pixie | Into_the_Story | Opportunistic_Dragon | Venerable_Knight | Fell_the_Pheasant | Giant_Opportunity |
| 174 | Outflank | Foreboding_Fruit | Tuinvale_Treefolk | Gadwick_the_Wizened | Deafening_Silence | Thunderous_Snapper | Crashing_Drawbridge | Blacklance_Paragon | True_Love's_Kiss | Syr_Faren_the_Hengehammer | Wishful_Merfolk | Mystic_Sanctuary | Roving_Keep | Silverflame_Ritual | Tall_as_a_Beanstalk |
| 175 | Cauldron's_Gift | Into_the_Story | Scalding_Cauldron | Charming_Prince | Castle_Garenbrig | Outflank | Cauldron_Familiar | Syr_Alin_the_Lion's_Claw | Prized_Griffin | Steelgaze_Griffin | Piper_of_the_Swarm | Fling | Jousting_Dummy | Signpost_Scarecrow | Inquisitive_Puppet |
| 176 | Castle_Ardenvale | Questing_Beast | Festive_Funeral | Bonecrusher_Giant | Once_and_Future | Drown_in_the_Loch | Garenbrig_Paladin | All_That_Glitters | Scalding_Cauldron | Shining_Armor | Memory_Theft | Wishful_Merfolk | Eye_Collector | Savvy_Hunter | Beloved_Princess |
| 177 | Specter's_Shriek | Once_Upon_a_Time | Garenbrig_Squire | Slaying_Fire | Animating_Faerie | Castle_Garenbrig | Wintermoor_Commander | Escape_to_the_Wilds | Giant's_Skewer | Silverflame_Squire | Skullknocker_Ogre | Opt | Thrill_of_Possibility | Silverflame_Squire | Cauldron_Familiar |
| 178 | Barge_In | Maraleaf_Rider | Witch's_Vengeance | True_Love's_Kiss | Foulmire_Knight | Clockwork_Servant | Crystal_Slipper | Fae_of_Wishes | Opt | Outflank | Reave_Soul | Garenbrig_Squire | Idyllic_Grange | Raging_Redcap | Ardenvale_Paladin |
| 179 | Reave_Soul | Edgewall_Innkeeper | Embereth_Paladin | Idyllic_Grange | Wolf's_Quarry | True_Love's_Kiss | Garruk_Cursed_Huntsman | Faeburrow_Elder | Fortifying_Provisions | Turn_into_a_Pumpkin | Frogify | Sorcerous_Spyglass | Fae_of_Wishes | Burning-Yard_Trainer | Keeper_of_Fables |
| 180 | Bloodhaze_Wolverine | Gilded_Goose | Wildborn_Preserver | Raging_Redcap | Happily_Ever_After | Into_the_Story | Lost_Legion | Keeper_of_Fables | Unexplained_Vision | Bartered_Cow | Bog_Naughty | Wandermare | Animating_Faerie | Bartered_Cow | Torbran_Thane_of_Red_Fell |
| 181 | Idyllic_Grange | Mystical_Dispute | Sporecap_Spider | Syr_Carah_the_Bold | Castle_Embereth | Skullknocker_Ogre | Wishful_Merfolk | Revenge_of_Ravens | Reaper_of_Night | Corridor_Monitor | Fervent_Champion | Clockwork_Servant | Youthful_Knight | Archon_of_Absolution | Oko_Thief_of_Crowns |
| 182 | Giant_Killer | Castle_Locthwain | Maraleaf_Rider | So_Tiny | Fervent_Champion | Mistford_River_Turtle | Fling | Hushbringer | Knight_of_the_Keep | Tempting_Witch | Heraldic_Banner | Embereth_Shieldbreaker | Prized_Griffin | Searing_Barrage | Fireborn_Knight |
| 183 | Witch's_Vengeance | Mad_Ratter | Lovestruck_Beast | Escape_to_the_Wilds | Midnight_Clock | Arcanist's_Owl | Rosethorn_Acolyte | Overwhelmed_Apprentice | Gadwick_the_Wizened | Moonlit_Scavengers | Scalding_Cauldron | Henge_Walker | Righteousness | Outmuscle | Giant's_Skewer |
| 184 | Linden_the_Steadfast_Queen | Piper_of_the_Swarm | Steelclaw_Lance | Beloved_Princess | Run_Away_Together | Glass_Casket | Escape_to_the_Wilds | Gilded_Goose | Flutterfox | The_Great_Henge | Castle_Vantress | Mistford_River_Turtle | Locthwain_Gargoyle | Henge_Walker | Happily_Ever_After |
| 185 | True_Love's_Kiss | Witch's_Vengeance | Burning-Yard_Trainer | Midnight_Clock | Lochmere_Serpent | Vantress_Paladin | Fires_of_Invention | Outmuscle | Forever_Young | Fell_the_Pheasant | Clockwork_Servant | Unexplained_Vision | Ardenvale_Paladin | Wintermoor_Commander | Edgewall_Innkeeper |
| 186 | Memory_Theft | Bloodhaze_Wolverine | Weaselback_Redcap | Syr_Alin_the_Lion's_Claw | Questing_Beast | Fabled_Passage | Drown_in_the_Loch | Acclaimed_Contender | Run_Away_Together | Rally_for_the_Throne | Thunderous_Snapper | The_Great_Henge | Merfolk_Secretkeeper | Golden_Egg | Wishclaw_Talisman |
| 187 | Prized_Griffin | Locthwain_Paladin | Bog_Naughty | Rally_for_the_Throne | Syr_Elenora_the_Discerning | Robber_of_the_Rich | Barrow_Witches | Oathsworn_Knight | Rankle_Master_of_Pranks | Curious_Pair | Syr_Konrad_the_Grim | Tall_as_a_Beanstalk | Rosethorn_Halberd | Kenrith's_Transformation | Rally_for_the_Throne |
| 188 | Gingerbrute | The_Cauldron_of_Eternity | Edgewall_Innkeeper | Castle_Vantress | Gilded_Goose | Turn_into_a_Pumpkin | Jousting_Dummy | Wildborn_Preserver | Syr_Elenora_the_Discerning | Faerie_Vandal | Mistford_River_Turtle | Moonlit_Scavengers | Wildwood_Tracker | Glass_Casket | Cauldron's_Gift |
| 189 | Locthwain_Gargoyle | Gingerbread_Cabin | Oathsworn_Knight | Wishful_Merfolk | Outlaws'_Merriment | Once_and_Future | Outflank | Wicked_Wolf | Malevolent_Noble | Wishful_Merfolk | Sorcerer's_Broom | Jousting_Dummy | Bartered_Cow | Return_of_the_Wildspeaker | Sorcerous_Spyglass |
| 190 | Revenge_of_Ravens | Castle_Vantress | Garenbrig_Carver | Giant_Killer | Revenge_of_Ravens | Scalding_Cauldron | All_That_Glitters | Shepherd_of_the_Flock | Stolen_by_the_Fae | Fortifying_Provisions | Clackbridge_Troll | Wolf's_Quarry | Opt | Dwarven_Mine | Syr_Faren_the_Hengehammer |
| 191 | Lonesome_Unicorn | Deafening_Silence | The_Great_Henge | Youthful_Knight | Robber_of_the_Rich | Charmed_Sleep | Forever_Young | The_Circle_of_Loyalty | Shepherd_of_the_Flock | Witching_Well | Wicked_Guardian | Dwarven_Mine | Burning-Yard_Trainer | Maraleaf_Rider | Gingerbrute |
| 192 | Reaper_of_Night | Kenrith's_Transformation | Merchant_of_the_Vale | Weaselback_Redcap | Witch's_Vengeance | Oakhame_Ranger | Signpost_Scarecrow | Sorcerer's_Broom | Witch's_Oven | Faerie_Guidemother | Specter's_Shriek | Fell_the_Pheasant | Joust | Outflank | Return_of_the_Wildspeaker |
| 193 | Bake_into_a_Pie | Signpost_Scarecrow | Embereth_Shieldbreaker | Shining_Armor | Bog_Naughty | Unexplained_Vision | Kenrith's_Transformation | Worthy_Knight | Charmed_Sleep | Garenbrig_Paladin | Ferocity_of_the_Wilds | Castle_Garenbrig | Merchant_of_the_Vale | Once_and_Future | Shinechaser |
| 194 | Embercleave | Faerie_Vandal | Reaper_of_Night | Silverflame_Ritual | Specter's_Shriek | Outlaws'_Merriment | Claim_the_Firstborn | Fabled_Passage | Foreboding_Fruit | Opt | Steelgaze_Griffin | Thrill_of_Possibility | Mystical_Dispute | Wolf's_Quarry | Feasting_Troll_King |
| 195 | Murderous_Rider | Lash_of_Thorns | Malevolent_Noble | Claim_the_Firstborn | Flaxen_Intruder | Mad_Ratter | Venerable_Knight | Syr_Faren_the_Hengehammer | Witching_Well | Syr_Elenora_the_Discerning | Tome_Raider | Gingerbread_Cabin | Weapon_Rack | Shining_Armor | Righteousness |
| 196 | Epic_Downfall | Castle_Garenbrig | Wicked_Guardian | The_Cauldron_of_Eternity | Witch's_Oven | Dance_of_the_Manse | Reaper_of_Night | Wishclaw_Talisman | Witch's_Vengeance | Queen_of_Ice | Festive_Funeral | Giant_Opportunity | Embereth_Shieldbreaker | Embereth_Shieldbreaker | Castle_Locthwain |
| 197 | Order_of_Midnight | Malevolent_Noble | Beanstalk_Giant | Embereth_Paladin | The_Magic_Mirror | Lonesome_Unicorn | Curious_Pair | Witch's_Vengeance | Piper_of_the_Swarm | Run_Away_Together | Moonlit_Scavengers | Fervent_Champion | Charmed_Sleep | Ogre_Errant | Wicked_Wolf |
| 198 | Fling | Tome_Raider | Rosethorn_Acolyte | Opt | Return_of_the_Wildspeaker | Improbable_Alliance | Cauldron's_Gift | Feasting_Troll_King | Tome_Raider | Mantle_of_Tides | Epic_Downfall | So_Tiny | Knight_of_the_Keep | Joust | The_Cauldron_of_Eternity |
| 199 | Fortifying_Provisions | Lochmere_Serpent | Syr_Faren_the_Hengehammer | Mystical_Dispute | Wicked_Wolf | Merchant_of_the_Vale | Inquisitive_Puppet | Questing_Beast | Oathsworn_Knight | Oakhame_Adversary | Brimstone_Trebuchet | Overwhelmed_Apprentice | Syr_Elenora_the_Discerning | Sporecap_Spider | The_Great_Henge |
| 200 | Mad_Ratter | Vantress_Paladin | Redcap_Raiders | Harmonious_Archon | The_Royal_Scions | Brimstone_Trebuchet | Garenbrig_Carver | Order_of_Midnight | Acclaimed_Contender | Animating_Faerie | Redcap_Raiders | Return_to_Nature | All_That_Glitters | Curious_Pair | Lovestruck_Beast |
| 201 | Claim_the_Firstborn | Unexplained_Vision | Wicked_Wolf | Specter's_Shriek | Savvy_Hunter | Rally_for_the_Throne | Weapon_Rack | Syr_Konrad_the_Grim | Oko_Thief_of_Crowns | Giant_Killer | Inquisitive_Puppet | Golden_Egg | Didn't_Say_Please | Lovestruck_Beast | Rosethorn_Halberd |
| 202 | Witch's_Cottage | Roving_Keep | Feasting_Troll_King | Into_the_Story | Dance_of_the_Manse | Bonecrusher_Giant | Once_and_Future | Lucky_Clover | Shining_Armor | Beloved_Princess | Lost_Legion | Once_Upon_a_Time | Overwhelmed_Apprentice | Sundering_Stroke | Savvy_Hunter |
| 203 | Foreboding_Fruit | Rosethorn_Acolyte | Seven_Dwarves | Castle_Embereth | Castle_Locthwain | Spinning_Wheel | Idyllic_Grange | Rampart_Smasher | Clackbridge_Troll | Mistford_River_Turtle | Turn_into_a_Pumpkin | Roving_Keep | Lonesome_Unicorn | Bonecrusher_Giant | Irencrag_Feat |
| 204 | Bonecrusher_Giant | Wishclaw_Talisman | Forever_Young | Realm-Cloaked_Giant | Edgewall_Innkeeper | Dwarven_Mine | Witch's_Cottage | Brazen_Borrower | Moonlit_Scavengers | Tall_as_a_Beanstalk | Embereth_Paladin | Folio_of_Fancies | Fortifying_Provisions | Insatiable_Appetite | Castle_Embereth |
| 205 | Deafening_Silence | The_Great_Henge | Foreboding_Fruit | Mystic_Sanctuary | Bonecrusher_Giant | Syr_Elenora_the_Discerning | Once_Upon_a_Time | Merfolk_Secretkeeper | Glass_Casket | Gilded_Goose | Syr_Elenora_the_Discerning | Embercleave | Flutterfox | Wildwood_Tracker | Syr_Alin_the_Lion's_Claw |
| 206 | Harmonious_Archon | Reaper_of_Night | Sundering_Stroke | Wandermare | Improbable_Alliance | Archon_of_Absolution | Giant_Opportunity | The_Great_Henge | Tempting_Witch | Syr_Alin_the_Lion's_Claw | Wishclaw_Talisman | Crystal_Slipper | True_Love's_Kiss | Improbable_Alliance | Doom_Foretold |
| 207 | Faerie_Guidemother | Tuinvale_Treefolk | Rankle_Master_of_Pranks | Eye_Collector | Irencrag_Feat | Acclaimed_Contender | Sporecap_Spider | Flutterfox | So_Tiny | So_Tiny | Animating_Faerie | Midnight_Clock | Frogify | Outlaws'_Merriment | Wildborn_Preserver |
| 208 | Dance_of_the_Manse | Irencrag_Pyromancer | Redcap_Melee | Thrill_of_Possibility | Sage_of_the_Falls | Fires_of_Invention | Garenbrig_Squire | Drown_in_the_Loch | Ardenvale_Paladin | Idyllic_Grange | Prophet_of_the_Peak | Signpost_Scarecrow | Mistford_River_Turtle | Wildborn_Preserver | Mysterious_Pathlighter |
| 209 | Glass_Casket | Doom_Foretold | Keeper_of_Fables | Deafening_Silence | Didn't_Say_Please | Bartered_Cow | Silverflame_Ritual | Murderous_Rider | Queen_of_Ice | Keeper_of_Fables | Raging_Redcap | Prophet_of_the_Peak | Outflank | Fortifying_Provisions | Rampart_Smasher |
| 210 | Skullknocker_Ogre | Clackbridge_Troll | Grumgully_the_Generous | Sorcerous_Spyglass | Rankle_Master_of_Pranks | Grumgully_the_Generous | Blow_Your_House_Down | Mirrormade | Locthwain_Paladin | Youthful_Knight | Mantle_of_Tides | Mirrormade | Silverflame_Ritual | Ardenvale_Tactician | Flaxen_Intruder |
| 211 | Beloved_Princess | Sage_of_the_Falls | Locthwain_Paladin | Knight_of_the_Keep | Merfolk_Secretkeeper | Prized_Griffin | Giant's_Skewer | Trapped_in_the_Tower | Faerie_Guidemother | Oko_Thief_of_Crowns | Lash_of_Thorns | Run_Away_Together | Embercleave | Deathless_Knight | Once_Upon_a_Time |
| 212 | Clackbridge_Troll | Insatiable_Appetite | Questing_Beast | Castle_Ardenvale | Vantress_Gargoyle | Idyllic_Grange | Locthwain_Gargoyle | Ayara_First_of_Locthwain | Venerable_Knight | Didn't_Say_Please | Foreboding_Fruit | Beanstalk_Giant | Wishful_Merfolk | Scorching_Dragonfire | Harmonious_Archon |
| 213 | Eye_Collector | Drown_in_the_Loch | Oakhame_Adversary | Righteousness | Mirrormade | Slaying_Fire | Maraleaf_Rider | Clackbridge_Troll | Golden_Egg | Frogify | Crystal_Slipper | Embereth_Paladin | Shining_Armor | Venerable_Knight | Charming_Prince |
| 214 | Opportunistic_Dragon | Rosethorn_Halberd | Raging_Redcap | Happily_Ever_After | Into_the_Story | Stolen_by_the_Fae | Tuinvale_Treefolk | Charming_Prince | Tournament_Grounds | Tome_Raider | Crashing_Drawbridge | Mantle_of_Tides | Shinechaser | Trapped_in_the_Tower | Fires_of_Invention |
| 215 | Charming_Prince | The_Royal_Scions | Lost_Legion | Ardenvale_Paladin | Frogify | Deafening_Silence | Oko_Thief_of_Crowns | Lovestruck_Beast | Hypnotic_Sprite | Gingerbread_Cabin | Giant's_Skewer | Rosethorn_Acolyte | Dwarven_Mine | Fierce_Witchstalker | Venerable_Knight |
| 216 | Rally_for_the_Throne | Mistford_River_Turtle | Garenbrig_Paladin | Tournament_Grounds | Steelclaw_Lance | Fireborn_Knight | Wildwood_Tracker | Stonecoil_Serpent | Youthful_Knight | Trail_of_Crumbs | Blow_Your_House_Down | Crashing_Drawbridge | Stolen_by_the_Fae | Linden_the_Steadfast_Queen | Heraldic_Banner |
| 217 | Torbran_Thane_of_Red_Fell | Mystic_Sanctuary | Barrow_Witches | Resolute_Rider | Mad_Ratter | Mysterious_Pathlighter | Rosethorn_Halberd | Piper_of_the_Swarm | Lost_Legion | Ardenvale_Tactician | Barge_In | Seven_Dwarves | Lucky_Clover | Rally_for_the_Throne | Rankle_Master_of_Pranks |
| 218 | Ferocity_of_the_Wilds | Witch's_Cottage | Joust | Lochmere_Serpent | Faerie_Vandal | Embereth_Shieldbreaker | Roving_Keep | Return_of_the_Wildspeaker | Maraleaf_Pixie | Hypnotic_Sprite | Joust | Corridor_Monitor | Run_Away_Together | Merchant_of_the_Vale | Castle_Ardenvale |
| 219 | Redcap_Raiders | Festive_Funeral | Ogre_Errant | Doom_Foretold | Wildborn_Preserver | Giant_Killer | Festive_Funeral | Resolute_Rider | Turn_into_a_Pumpkin | Wolf's_Quarry | Roving_Keep | Trail_of_Crumbs | Ogre_Errant | Idyllic_Grange | Smitten_Swordmaster |
| 220 | Silverflame_Squire | Happily_Ever_After | Deathless_Knight | Loch_Dragon | Castle_Vantress | Irencrag_Pyromancer | Doom_Foretold | Scalding_Cauldron | Silverflame_Squire | Oakhame_Ranger | Tournament_Grounds | Inquisitive_Puppet | Claim_the_Firstborn | Gilded_Goose | Maraleaf_Pixie |
| 221 | Realm-Cloaked_Giant | Garenbrig_Carver | Elite_Headhunter | Mirrormade | Fires_of_Invention | Moonlit_Scavengers | Gingerbread_Cabin | Epic_Downfall | Barrow_Witches | Wildborn_Preserver | Ayara_First_of_Locthwain | Weapon_Rack | Hypnotic_Sprite | Syr_Alin_the_Lion's_Claw | Murderous_Rider |
| 222 | Mysterious_Pathlighter | Eye_Collector | Piper_of_the_Swarm | Brimstone_Trebuchet | Overwhelmed_Apprentice | Rampart_Smasher | Irencrag_Feat | Garruk_Cursed_Huntsman | Lonesome_Unicorn | Glass_Casket | Burning-Yard_Trainer | Witching_Well | Ardenvale_Tactician | Thrill_of_Possibility | Locthwain_Paladin |
| 223 | Redcap_Melee | Return_to_Nature | Brimstone_Trebuchet | Wintermoor_Commander | Folio_of_Fancies | Fae_of_Wishes | Wishclaw_Talisman | Linden_the_Steadfast_Queen | Faerie_Vandal | Prized_Griffin | Vantress_Paladin | Tuinvale_Treefolk | Vantress_Paladin | Trail_of_Crumbs | Embercleave |
| 224 | Ayara_First_of_Locthwain | Yorvo_Lord_of_Garenbrig | Belle_of_the_Brawl | Torbran_Thane_of_Red_Fell | Turn_into_a_Pumpkin | Searing_Barrage | Fortifying_Provisions | Clockwork_Servant | Steelclaw_Lance | Vantress_Paladin | Weaselback_Redcap | Animating_Faerie | Tome_Raider | Youthful_Knight | Castle_Garenbrig |
| 225 | Trapped_in_the_Tower | Sporecap_Spider | Clackbridge_Troll | Faeburrow_Elder | Redcap_Melee | Emry_Lurker_of_the_Loch | Sorcerous_Spyglass | Animating_Faerie | Trapped_in_the_Tower | Maraleaf_Rider | Rankle_Master_of_Pranks | Witch's_Oven | Shepherd_of_the_Flock | The_Great_Henge | Tournament_Grounds |
| 226 | Bartered_Cow | Opt | Revenge_of_Ravens | Mad_Ratter | Gadwick_the_Wizened | Torbran_Thane_of_Red_Fell | Ardenvale_Paladin | Oakhame_Ranger | Bog_Naughty | Wildwood_Tracker | Locthwain_Gargoyle | Feasting_Troll_King | Brazen_Borrower | Mad_Ratter | All_That_Glitters |
| 227 | Shambling_Suit | Memory_Theft | Blacklance_Paragon | Hushbringer | Fae_of_Wishes | Syr_Carah_the_Bold | Bartered_Cow | Yorvo_Lord_of_Garenbrig | Inspiring_Veteran | Silverflame_Ritual | Tempting_Witch | Brimstone_Trebuchet | Fling | Giant_Killer | The_Circle_of_Loyalty |
| 228 | Wicked_Guardian | Mantle_of_Tides | Torbran_Thane_of_Red_Fell | Irencrag_Feat | Stolen_by_the_Fae | Joust | Insatiable_Appetite | Deathless_Knight | Lucky_Clover | Outmuscle | Ogre_Errant | Locthwain_Gargoyle | Skullknocker_Ogre | Questing_Beast | Blacklance_Paragon |
| 229 | Resolute_Rider | Wildwood_Tracker | Smitten_Swordmaster | Venerable_Knight | Hypnotic_Sprite | Enchanted_Carriage | Castle_Garenbrig | Archon_of_Absolution | Reave_Soul | Gingerbrute | Stormfist_Crusader | Merchant_of_the_Vale | Arcanist's_Owl | Embercleave | Wandermare |
| 230 | All_That_Glitters | Wolf's_Quarry | Fierce_Witchstalker | Vantress_Gargoyle | Doom_Foretold | Charming_Prince | Eye_Collector | Glass_Casket | Blacklance_Paragon | Rosethorn_Halberd | Locthwain_Paladin | Flaxen_Intruder | Steelgaze_Griffin | Harmonious_Archon | Worthy_Knight |
| 231 | Witch's_Oven | Cauldron's_Gift | Foulmire_Knight | Didn't_Say_Please | Irencrag_Pyromancer | Trapped_in_the_Tower | Shining_Armor | Stolen_by_the_Fae | Worthy_Knight | Giant_Opportunity | Barrow_Witches | Garenbrig_Carver | Mantle_of_Tides | Syr_Carah_the_Bold | Hushbringer |
| 232 | Wishclaw_Talisman | The_Magic_Mirror | Rimrock_Knight | Drown_in_the_Loch | Shinechaser | Scorching_Dragonfire | Flaxen_Intruder | Vantress_Gargoyle | Syr_Konrad_the_Grim | Brazen_Borrower | Weapon_Rack | The_Royal_Scions | Beloved_Princess | Slaying_Fire | Oathsworn_Knight |
| 233 | Castle_Locthwain | Fell_the_Pheasant | Bonecrusher_Giant | Fires_of_Invention | Piper_of_the_Swarm | Sage_of_the_Falls | True_Love's_Kiss | Midnight_Clock | Epic_Downfall | Questing_Beast | Corridor_Monitor | Curious_Pair | Faerie_Vandal | Gingerbread_Cabin | Belle_of_the_Brawl |
| 234 | Shepherd_of_the_Flock | Flaxen_Intruder | Embercleave | Fervent_Champion | Skullknocker_Ogre | Castle_Embereth | Maraleaf_Pixie | Folio_of_Fancies | Covetous_Urge | Trapped_in_the_Tower | Witch's_Cottage | Oko_Thief_of_Crowns | Blow_Your_House_Down | Yorvo_Lord_of_Garenbrig | Garruk_Cursed_Huntsman |
| 235 | Shinechaser | Wishful_Merfolk | Syr_Carah_the_Bold | The_Magic_Mirror | Claim_the_Firstborn | Irencrag_Feat | Righteousness | Gadwick_the_Wizened | Bake_into_a_Pie | Feasting_Troll_King | Malevolent_Noble | Gingerbrute | Faerie_Guidemother | Bloodhaze_Wolverine | Faeburrow_Elder |
| 236 | Dwarven_Mine | Tall_as_a_Beanstalk | Order_of_Midnight | The_Royal_Scions | Escape_to_the_Wilds | Wandermare | Beloved_Princess | Rankle_Master_of_Pranks | Animating_Faerie | Charmed_Sleep | Steelclaw_Lance | Thunderous_Snapper | Embereth_Paladin | Acclaimed_Contender | Wintermoor_Commander |
| 237 | Archon_of_Absolution | Specter's_Shriek | Searing_Barrage | Fireborn_Knight | Drown_in_the_Loch | Maraleaf_Pixie | Lash_of_Thorns | Thunderous_Snapper | Syr_Alin_the_Lion's_Claw | Insatiable_Appetite | Blacklance_Paragon | Sorcerer's_Broom | Mysterious_Pathlighter | The_Circle_of_Loyalty | Fervent_Champion |
| 238 | Bog_Naughty | Faeburrow_Elder | Outmuscle | Overwhelmed_Apprentice | Mystical_Dispute | Opportunistic_Dragon | Memory_Theft | Giant_Killer | Belle_of_the_Brawl | Linden_the_Steadfast_Queen | Jousting_Dummy | Merfolk_Secretkeeper | Crystal_Slipper | Giant_Opportunity | Steelclaw_Lance |
| 239 | Malevolent_Noble | Wicked_Guardian | Epic_Downfall | Linden_the_Steadfast_Queen | Ferocity_of_the_Wilds | Castle_Vantress | Knight_of_the_Keep | Dance_of_the_Manse | Wintermoor_Commander | Realm-Cloaked_Giant | Dwarven_Mine | Shambling_Suit | Bloodhaze_Wolverine | Feasting_Troll_King | Deathless_Knight |
| 240 | Flutterfox | Garenbrig_Squire | Opportunistic_Dragon | Improbable_Alliance | Giant_Opportunity | Happily_Ever_After | Wolf's_Quarry | Shinechaser | Ardenvale_Tactician | Shinechaser | Signpost_Scarecrow | Improbable_Alliance | Ferocity_of_the_Wilds | Syr_Faren_the_Hengehammer | Yorvo_Lord_of_Garenbrig |
| 241 | Tempting_Witch | Steelgaze_Griffin | Murderous_Rider | Acclaimed_Contender | Cauldron_Familiar | Midnight_Clock | Fell_the_Pheasant | Harmonious_Archon | Foulmire_Knight | Fierce_Witchstalker | Belle_of_the_Brawl | Lucky_Clover | Queen_of_Ice | Redcap_Melee | Oakhame_Ranger |
| 242 | Cauldron_Familiar | Savvy_Hunter | Slaying_Fire | The_Circle_of_Loyalty | Trail_of_Crumbs | Realm-Cloaked_Giant | Tall_as_a_Beanstalk | Henge_Walker | Mysterious_Pathlighter | Wicked_Wolf | Oathsworn_Knight | Torbran_Thane_of_Red_Fell | Silverflame_Squire | Inspiring_Veteran | Acclaimed_Contender |
| 243 | Rankle_Master_of_Pranks | Covetous_Urge | Syr_Konrad_the_Grim | Merfolk_Secretkeeper | Grumgully_the_Generous | Redcap_Melee | Return_to_Nature | Lochmere_Serpent | The_Circle_of_Loyalty | Thunderous_Snapper | Emry_Lurker_of_the_Loch | Mad_Ratter | Raging_Redcap | Wicked_Wolf | Seven_Dwarves |
| 244 | Sorcerer's_Broom | Deathless_Knight | Reave_Soul | Worthy_Knight | Brazen_Borrower | Castle_Ardenvale | Happily_Ever_After | Realm-Cloaked_Giant | Murderous_Rider | Harmonious_Archon | Loch_Dragon | Edgewall_Innkeeper | Barge_In | Fireborn_Knight | Linden_the_Steadfast_Queen |
| 245 | Fireborn_Knight | Improbable_Alliance | Rampart_Smasher | Folio_of_Fancies | Wishclaw_Talisman | Faeburrow_Elder | Tournament_Grounds | Covetous_Urge | Resolute_Rider | Archon_of_Absolution | Shambling_Suit | Irencrag_Pyromancer | Weaselback_Redcap | Worthy_Knight | Elite_Headhunter |
| 246 | Piper_of_the_Swarm | Wandermare | Scorching_Dragonfire | Outlaws'_Merriment | Stormfist_Crusader | Sundering_Stroke | Specter's_Shriek | Shambling_Suit | Order_of_Midnight | Flutterfox | Henge_Walker | Emry_Lurker_of_the_Loch | Redcap_Raiders | Rampart_Smasher | Resolute_Rider |
| 247 | Seven_Dwarves | Ayara_First_of_Locthwain | Bake_into_a_Pie | Irencrag_Pyromancer | Maraleaf_Pixie | Seven_Dwarves | Inspiring_Veteran | Emry_Lurker_of_the_Loch | Smitten_Swordmaster | Seven_Dwarves | Covetous_Urge | Rampart_Smasher | Rimrock_Knight | Oakhame_Ranger | Ayara_First_of_Locthwain |
| 248 | Elite_Headhunter | Garruk_Cursed_Huntsman | Garruk_Cursed_Huntsman | Inspiring_Veteran | Oko_Thief_of_Crowns | Escape_to_the_Wilds | Deafening_Silence | Arcanist's_Owl | Arcanist's_Owl | Arcanist's_Owl | Elite_Headhunter | Loch_Dragon | Loch_Dragon | Irencrag_Pyromancer | Stormfist_Crusader |
Third Prior: Staying Open Decays over Time
Yea, obviously in my head it's estimations not calculations, but that is pretty much how I see it. Lots of value early-mid pack 1, then a huge drop off after the early picks in pack 2 bc being open through then at least means you can get broken cards in any color in early pack 2.
— Ben Stark (@BenS_MTG) January 9, 2020
Ben Stark’s article, Drafting the Hard Way (also discussed in his course here), is considered to be one of the most influential and fundamental pieces of Limited theory. It can't be summarized by an easily actionable heuristic like “take removal highly”. It’s a philosophy that describes draft navigation agnostic of format. It’s a card evaluation framework that embeds format context alongside staying open to greatly increase the probability that the drafter ends up in the proper archetype for their seat.
The math described in the previous section is good for teaching the bot how to commit to an archetype, but in consequence that leads to marrying early picks a high percentage of the time. Because of this, I updated my math with a learned function to simulate the concept of “Drafting the Hard Way.”
As always, discerning how to introduce math corresponding to an abstract concept is no easy feat. I knew that a function representing how to stay open would decay, as eventually a drafter is required to solidify into an archetype. But where would this decaying factor — let’s call it λt where t is the current pick of the draft — fit into the math?
After spending some time thinking, I decided to model “Drafting the Hard Way” as a smoothing function over archetypal bias that decays over time. What this means is that, at Pack 1 Pick 2, there is still a strong bias towards every archetype even if the first pick was a fantastic red card. There is still, by definition, a larger bias towards red, but this math minimizes the delta between the value of red cards and other cards at Pack 1 Pick 2. Thereby the math describing how the bot picks cards is altered in the following way:
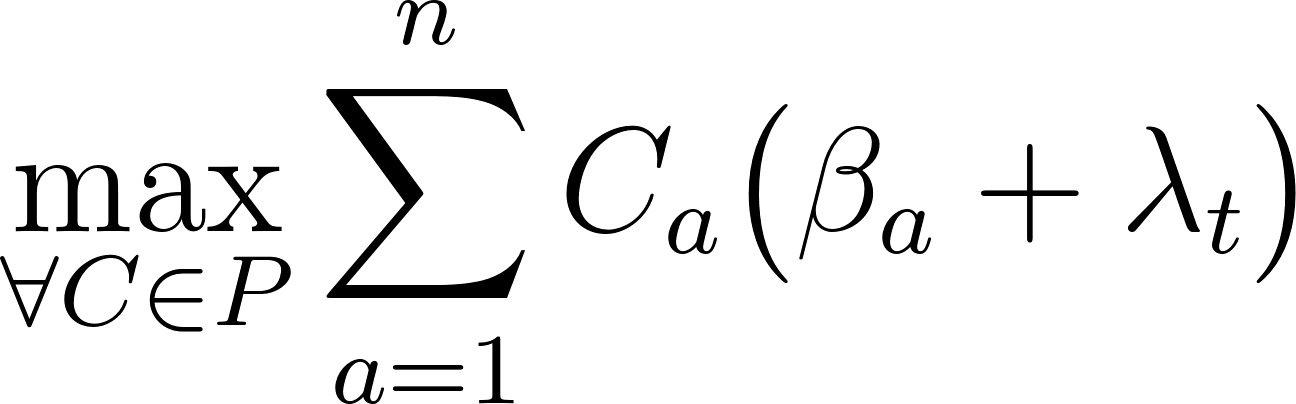
Effectively this is like simulating a draft pool with good cards in every archetype. The best card in any archetype is represented with a matrix weight between 1 and 1.2, with planeswalkers as exceptions (The Royal Scions, Garruk, and Oko are between 1.6 and 1.8). It's important to note that this is learned without a representation of card type. The planeswalkers jumped to the top because people take them so highly. If The Scarab God — one of the best Draft cards of all time — was in the format, it would also have a comparably high weight.
Hence, when λt > 1, the bot is behaving as if it had at least one of the best cards in every archetype. This clearly demonstrates that, for the first couple picks, the bot takes the best cards out of the pack. However, it’s not until the beginning of Pack 2 where this smoothing function decays under 1, which means the bot should be able to switch colors if necessary up until that point.
To demonstrate this, here are two draft logs where the bot pivots into the open archetype even though it started with extremely strong cards outside of it:
This begs the question: “how do I know that the bot wouldn’t be able to pivot without this logic”? To test this, I trained two versions of the bot, one with λt and one without. The difference is so much larger than I expected!
In both drafts above, the bot without the structure for drafting the hard way can’t deviate when necessary. It picks Tuinvale Treefolk over Ardenvale Tactician Pack 1 Pick 3 in the draft starting with Oko, Thief of Crowns. I could see taking So Tiny, but this just goes to show the issue without the staying open logic as Garenbrig Paladin must have added too much to Oko’s green bias without the smoothing function.
In the other draft, the simpler bot takes Locthwain Paladin over Inspiring Veteran Pack 1 Pick 5, which I believe is an egregious pick, but I guess makes sense if there’s no way to fight the bias from the other cards in the pool.
If these were the only examples I gave, it would look like I cherry-picked them to illustrate my point. So, I created a table with 8 copies of the staying open bot, and a separate table with 8 copies of the simpler bot. I then simulated 5,000 full-table drafts, and gave the different tables of bots the identical simulated drafts to see what the different bots would do. It’s not a perfect exploration of the delta between these bots, but given how stark the difference is, I believe it is sufficient.
The bot with this learned decaying smoothing function could cast the card it first picked 64% of the time. The bot without it could cast the card it first picked 77% of the time. And, in the data they were trained on, the humans could cast their first pick 81% of the time.
I believe that an overwhelming majority of expert drafters would agree that both 81%, and even 77%, are much higher than optimal, and that my bot represents closer to the ideal percentage. However, it’s a very common mistake in less experienced players, and so it’s not surprising that the training dataset has this quality.
The fact that the model learned a decaying structure that both myself and Ben Stark believe properly represents this fundamental draft philosophy and this version of the model can largely deviate from the mistakes in the dataset using this technique is truly amazing. Furthermore, this demonstrates that introducing priors according to the fundamentals ofl limited theory into the math that governs draft AI is a fruitful pursuit, and I will continue to explore these types of structures and complexities!
How Well Did it Do?
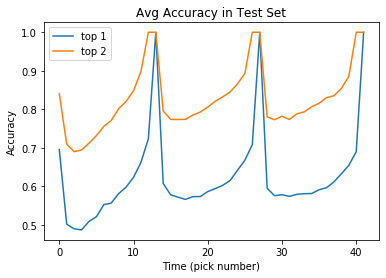
Bot pick accuracy % by pick number
The above plot demonstrates my algorithm’s ability to successfully predict what a human would pick given a draft pool and a pack of options. The blue line is the accuracy of the bot defined as the percentage of picks in the dataset at a given time where the bot would have taken the same card as the human (e.g. Pack 1 Pick 1 = 70%). The orange line represents that accuracy inflated by counting the bot’s second choice as well.
This yields an average accuracy of 63%, and that increases to 83% when considering the second pick. I believe this performance is sufficiently good because it’s unlikely the entire population of people in the dataset abide by the same rules. Many will disagree on picks, and hence it is likely impossible for any agent to achieve accuracy above some threshold.
While I do believe that there’s lots of room for improvement, I’m not certain how far away the upper-bound-threshold on performance is. Overall, I believe that this article was a sufficient demonstration that the algorithm I created is not only sufficient at draft navigation, but structured in a way such that we can analyze and understand how it works. I have achieved my initial goals I set out for, and am excited to take this to the next level in the near future as I improve it over the course of Theros Beyond Death!
Keep an eye on Draftsim soon for my next article when I'll have some very early Theros Beyond Death data to use in my model. And if this article sparked your technical interest, don't forget to check it out on Github!
As a final bonus for you, I was asked if I could show what an entire draft table would look like using my bot. Check it out below:



Add Comment