Last updated on May 20, 2024

Enraged Killbot vs Arcbound Ravager at the Rustvale Bridge | Illustrations by Alex Konstad, Daarken, & Craig J Spearingom, respectively
Today I've got some exciting news for you: Draftsim is part of a Magic data study that's being presented this week at the IEEE Conference on Games. The conference showcases some of the most cutting edge work in game technology and design. This year's conference is virtual (of course), and our paper is going to be presented in the morning (U.S. time) on August 19.
We're really proud, because this project has been years in the making. In fact, we believe this is the first ever peer-reviewed paper on draft bots in Magic. I hope this represents a new level of academic rigor for Magic analysis, helping us all eventually understand a lot more about the game and ourselves as drafters.
If you're more academically-inclined, here's the original paper. But if you're not, don't worry! I'm going to try to explain the findings in a simpler and more accessible way. No “scary math,” rest assured.
This paper was spearheaded by Henry Ward, with contributions from my previous draft data analysis co-conspirators Daniel Brooks (original creator of Draftsim), Bobby Mills, and Arseny Khakhalin.
Drafting in Magic Is Special…

Tolarian Scholar | Illustration by Sara Winters
We all love drafting a lot, but why?
Drafting in Magic is kind of special because of certain game mechanics that it has. It’s multiplayer, it has hidden information, and it asks you to choose between so many different cards. This is in contrast to something like Hearthstone's Arena drafting mode, which is single player and has no hidden information.
Just to give you an idea of the complexity of what's going on with draft in Magic…
In a full draft, a drafting agent sees a total of 315 cards and makes 45 consecutive decisions of which card to take, bringing the total number of direct card-to-card comparisons to 7,080.
AI solutions for drafting in Magic: the Gathering
On top of that, a 250-card set has about 1040 potential draft decks you could end up building. Wow! With that many possible outcomes, you can't really just brute force your way into a great drafting algorithm (and especially not an optimal one). So we had to try some other methods.

Brute Force | Illustration by Wayne Reynolds
The Paper's Goal
Our focus was more on mimicking player-like behavior than creating “optimal” decks.
Do you remember the infamous Merfolk Secretkeeper bot exploits in Throne of Eldraine draft? If we could make more human-like draft bots, it would go a long way toward creating a more “authentic-feeling” draft experience. Not to mention possibly reduce bad experiences, like playing against mill in every single match.
What this really means is that we want to predict the human’s pick given the choice of cards in the pack and cards already in the player’s collection (pool). And we want to find the most accurate agent (draft bot) to accomplish this goal.
The Data
The data for this study came from 107,949 user Core Set 2019 drafts on Draftsim's draft simulator. We used some parts of the dataset to train the BayesBot and the NNBot , and we used the rest to test all the bots against each other.
You may be wondering, why such an old set? It's really just the nature of the publishing and the peer review process.
Nevertheless, the lessons learned from this paper should be applicable to any typical Magic draft set.
Preliminary Work
We actually used some of the same concepts and visualizations that you saw in previous blog posts here on Draftsim to inform this work. Remember these synergy graphs?
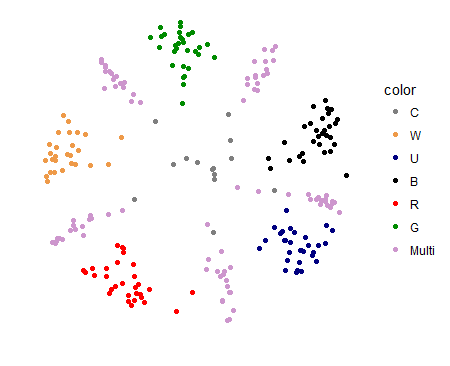
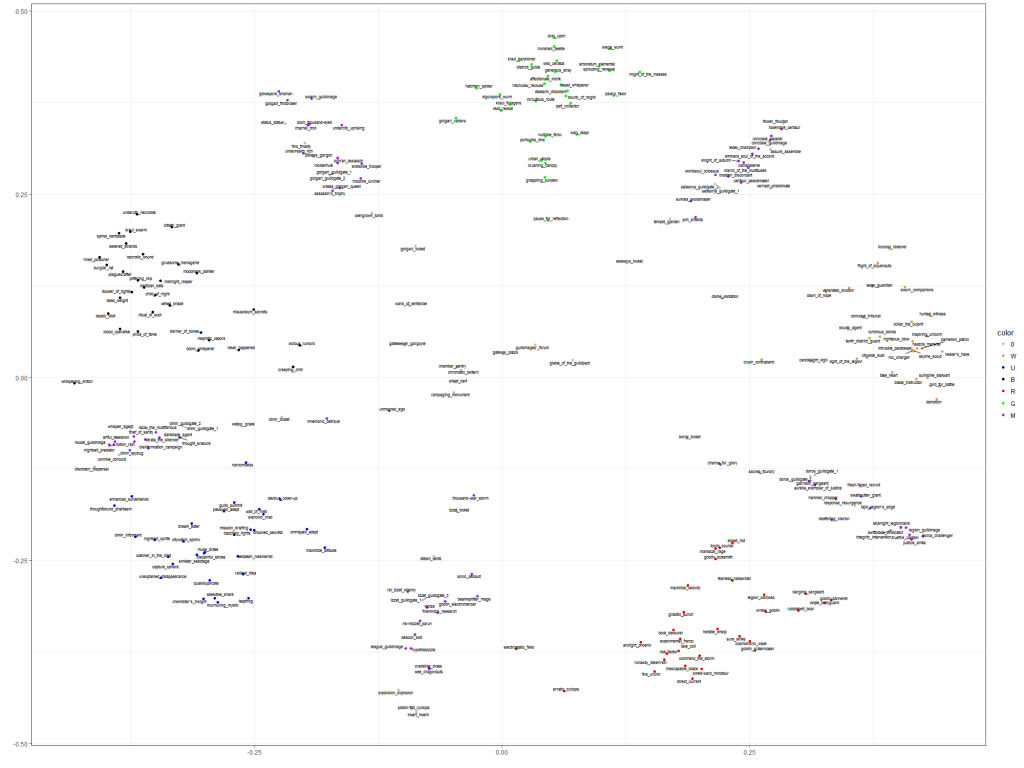
Guilds of Ravnica Synergy Plots
The images above are from our Guilds of Ravnica post. What you're looking at is pairs of cards that were often drafted alongside each other, called “synergy pairs.” If two cards are drafted together more frequently, this implies they work well together and will end up in decks together.
We used this process to create the BayesBot described below.
The Five Competitors
We ended up with five different draft bots to test out. These range from two very simple methods—the Baseline agents—and three more advanced bots—the Complex agents.
Here's a slide from Henry's presentation (don't worry, I'll break down what each of these means below):
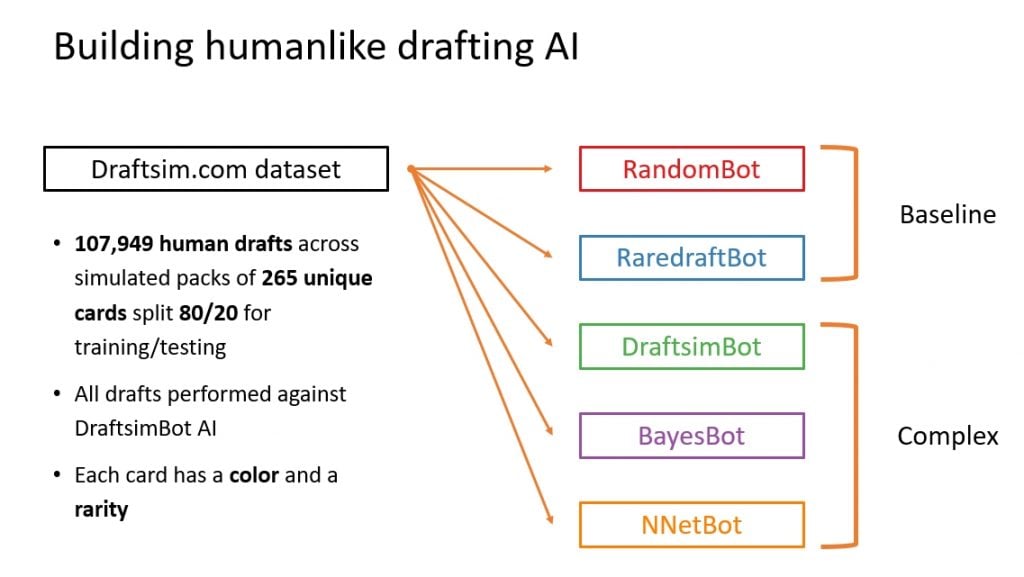
You can probably guess how some of these bots work, while others will take a little bit more explaining.
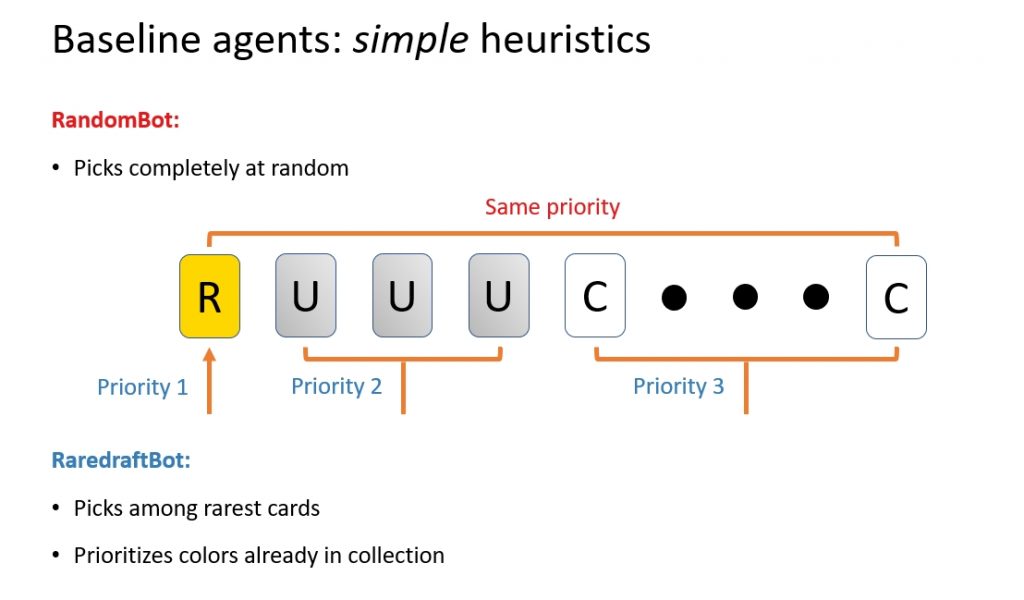
1. RandomBot and RaredraftBot
As you might guess, the RandomBot is very simple. It just picks cards out of the pack at random.
The RaredraftBot, affectionately also known as the “Beginner Bot,” is slightly better. And surprisingly effective. This “primitive heuristic agent” simply takes the rarest card in the pack. Ties are broken by picking a card in the color you have the most of.
It's a way more realistic baseline to compare against.
3. DraftsimBot
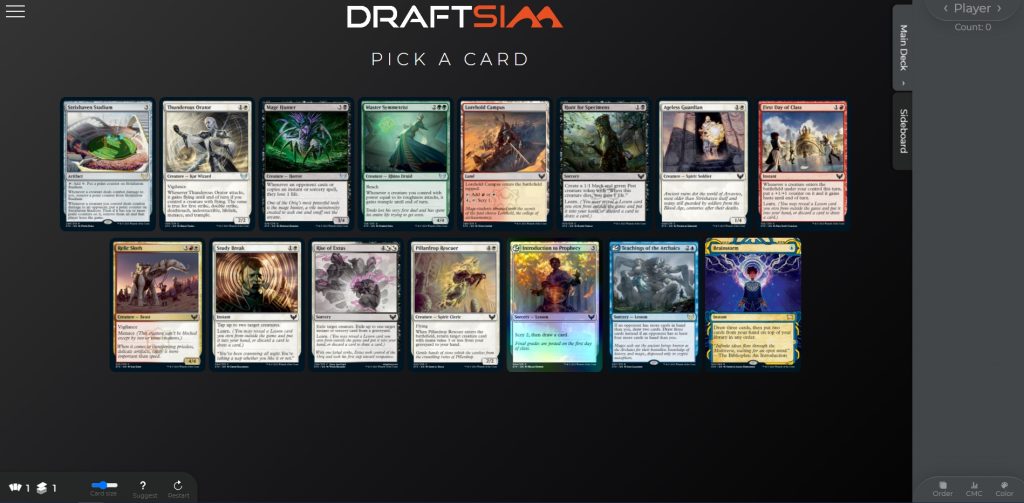
Ah, the beloved Draftsim bot. The same logic that powers the draft simulator on this very website and the draft assistant for Arena Tutor.
This is an “expert-tuned heuristic agent” that uses estimations of card strength and color matching. There's some explanation of how it works here, but if I had to put it simply, I'd say that the algorithm helps you pick the most powerful cards in the pack given the power level of the colors of the cards you already have. You can actually see all the draft ratings used in the simulator if you're curious.
While I'm very proud of it and the work we've done on it, it's time to see if we can do better!
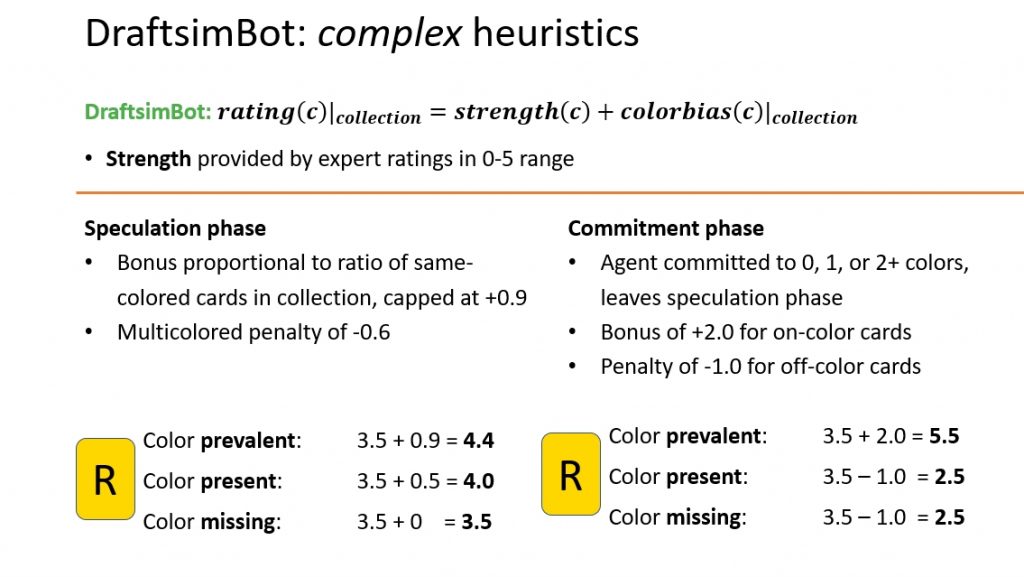
Here's Henry's graphic. One other important characteristic of the bot is that it drafts cards in two separate phases — speculation while it decides what colors to prioritize and commitment after it locks into those colors.
4. BayesBot
I'm pretty out of my depth here as we get into the more advanced math and machine learning stuff, but suffice it to say that the BayesBot uses probability.
This bot uses the “log likelihood” of the human user picking a given card from the pack. For the first pick, it picks the card that's most commonly picked by humans across all the cards in the pack. Then, for the other picks, it picks the most synergistic cards to add by assigning probabilities to all the potential picks (given your current ones) and determining the “most likely” pick based on the human picks in the data.

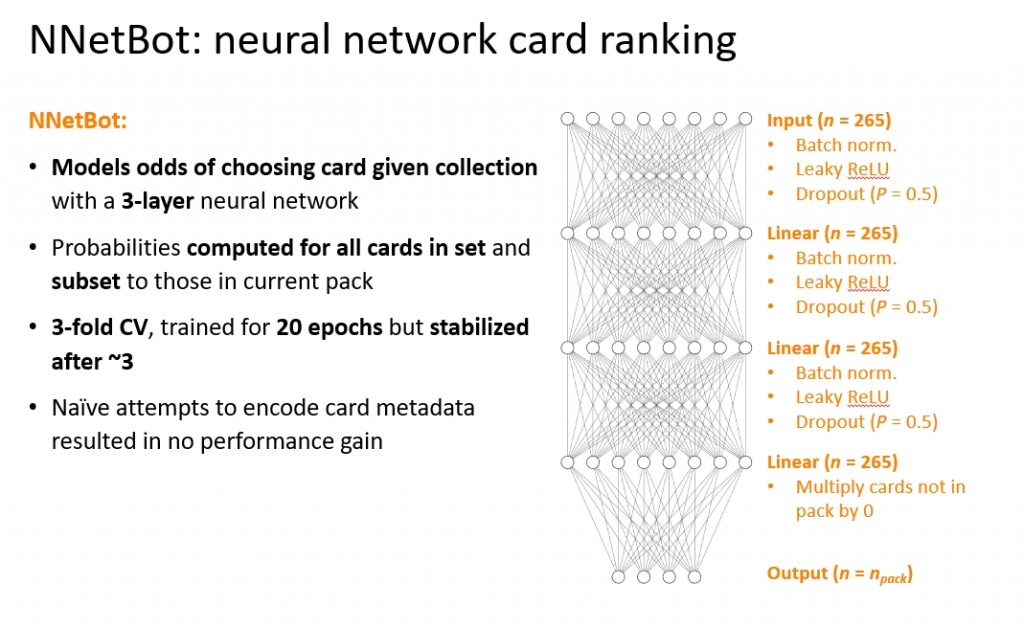
5. Neural Network Bot
Finally, the NNetBot is a “deep neural network agent” trained to predict human choices using a machine learning model. No card metadata attributes were taken into account, so the model chooses purely based on the probability of the pick given the cards in the pack and the current collection. Its picks aren't based on the color, keywords, text, or anything else.
This bot is conceptually similar to the BayesBot because it attempts to optimize the odds of choosing cards in a pack given the current collection (via math), but employs a machine learning strategy instead of one based purely on probabilities.
And the Winner Is…

Champion of Wits | Illustration by Even Amundsen
Now that I've introduced all the players, it's time to reveal the winner. Drumroll please…

The winner overall was the beloved NNetBot!
Not surprisingly, the Random and Raredraft bots were outperformed by the Draftsim, Bayes, and NN bots. It probably makes some intuitive sense to you that more complex methods designed to mimic human behavior would do better than picking cards at random or rare-drafting.
But the deep neural network did the best, winning with the highest prediction rate of human picks every step along the way.
Why? Well, neural networks are really good at this particular type of problem. Previous work such as the AlphaZero algorithm developed by DeepMind that can play chess, shogi, and go, has shown this too. Reinforcement learning-based bots are much more complex than our NNetbot, but good results still emerge when you use this type of tool.
Other Interesting Findings
So how emphatically did NNetBot win? See the orange line below:
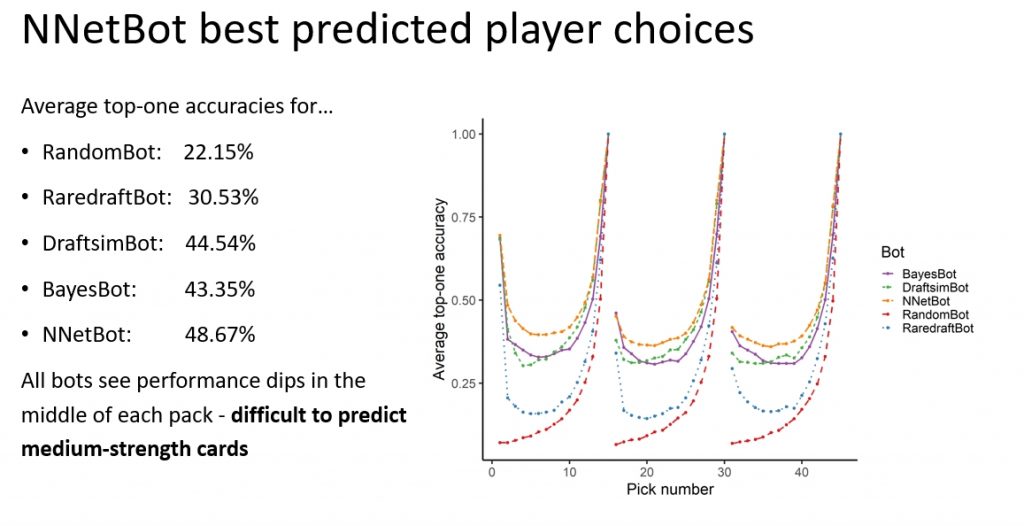
At every pick along the way, NNetBot beat out the competition. But as you can see in the middle of the pack there, its accuracy is still only in the 40% range. We think this is because medium-strong cards are also difficult for humans to pick between. Since humans don't even make the same picks as each other for these types of cards, it's not really possible to reach 100% accuracy in the middle of each pack.
To explain this in more detail, there's an interesting phenomenon going on here: pack position matters.
The where you are in a pack when making a pick is surprisingly relevant. The first pick of a pack is easier to estimate because we often pick the rares since they're more powerful.
The middle of the pack is actually the hardest to predict, because the power level of remaining candidates is relatively flat, so these picks typically depend on synergy with the cards already in the draft pool.
By the time you reach the end of the pack, you're left with the dregs. The cards are less powerful and less playable. Picks end up being easier to predict at this point because the pick might be based on something simple like the color of the card. Plus there are fewer cards to choose from.
So you see the highest prediction accuracy at the beginning and end of the pack.
What Could We (or You) Do Next?

Opportunity | Illustration by Ron Spears
If you’re a CS person or data scientist and want to take our work further, there's a ton of opportunity!
Can you do better than the models here? Can you make something awesome joining drafting and match results like Ryan Saxe's awesome win predictor? Can you bridge the gap between player-like behavior and building an optimal deck? This is a really exciting time in Magic with the explosion of data analysis from groups like us and others.
What other ideas do you have?
Check out the paper and the free dataset that we've given away!
Final Thoughts
If you want to support more MTG, draft data analysis, and general awesomeness like this, please follow us on Twitter and check out our free MTGA deck tracker, Arena Tutor. The more data we get, the cooler things we can build and write about!
See you next time.
Follow Draftsim for awesome articles and set updates:


3 Comments
Hi! Is the dataset available ? I’d love to explore it and test it myself :-). Also I think it could be cool to measure some pick agreement to see what’s the limit that we can aspire for, but that would probably mean doing another experiment because I guess the number of possibilites is too big.
Yes, full details are in the paper, but it is also here: https://draftsim.com/draft-data/
Thanks a lot! I’ll let you know if I find anything interesting. And congrats on the paper!! That’s awesome 🙂
Add Comment